 Петр Кудеров
Петр Кудеров
Математические методы и нейронные сети в изучении искусственного интеллекта
Современная наука об искусственном интеллекте уделяет значительное внимание созданию математических методов и моделей обучения, в основном – на основе нейронных сетей, а также масштабированию решений узких задач в надежде решить задачи более сложные.
За последнее десятилетие успех в этом направлении был связан с обучением глубоких нейронных сетей, построенных на основе модели искусственного нейрона. Они называются ANN (Artificial Neural Networks) – искусственные нейронные сети. Исследователи также выделяют SNN (Spiking Neural Networks) – спайковые нейронные сети, которые строятся на более биологически правдоподобных, чем ANN, моделях нейронов - на спайковых или пирамидальных (например, Integrate-and-Fire, Hodkin-Huxley).
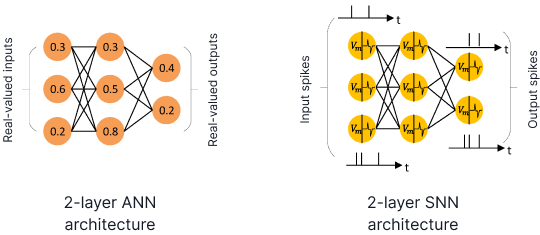
Искусственные и спайковые нейронные сети
Источник: MDPI
Различия между ANN и SNN
Разница заключается в том, что первые обмениваются вещественными числами, а вторые – спайками (единичными событиями, которые происходят в каждый конкретный момент времени). ANN обучаются с помощью градиентного спуска с алгоритмом обратного распространения ошибки, тогда как как SNN либо таким же методом (когда ML-специалисты пытаются использовать их для решения своих задач), либо по правилу Хебба (Spike timing-dependent plasticity, STDP).
Первый тип нейронных сетей относится к полносвязным, из-за чего большая доля нейронов участвует в вычислении результата. Второй – к разреженным, в которых только малая часть нейронов участвует в вычислении результата, что делает их более энергоэффективными. Несмотря на это, процессоров, «заточенных» под такой вид вычислений очень мало, и они пока еще не пользуются большой популярностью. Однако именно спайковые нейросети, биологически правдоподобные и гибридные модели и методы обучения ИИ считаются более перспективными с точки зрения прогресса в понимании принципов работы человеческого мозга за счет перспектив их использования в когнитивных науках, которые очень тесно связаны с исследованиями в области ИИ.
Тяжелая и критическая степень влияют на решение о госпитализации пациентов. Это означает, что применение ИИ могло повлиять на предотвращение перегрузку госпитальной системы здравоохранения в Москве.
Преимущества математических методов в когнитивных науках
С развитием вычислительных возможностей человечества становится все выгоднее и выгоднее строить гипотезы когнитивных наук на языке вычислительной математики. То есть, с помощью построения вычислительных моделей, которые можно реализовать в виде компьютерной программы и протестировать в компьютерных симуляциях.
Этот процесс аналогичен поиску лекарств в фармакологии, когда перед проведением реальных экспериментов в «мокрых» лабораториях сначала проводится обширный поиск наиболее перспективных формул лекарств в компьютерных симуляциях. Это позволяет сделать поиск масштабнее, дешевле и быстрее.
Полный доступ ко всей информации во время экспериментов — одно из главных преимуществ компьютерных симуляций для когнитивистики, роскошь, недоступная в экспериментах над мозгом человека и животного, ограниченных в возможностях наблюдения за отдельными нейронами и, тем более, в возможностях влияния на них. Исследуя реальный мозг, ученые не могут провести два разных эксперимента над копиями одного существа или создать существо с нужными параметрами мозга. Компьютерные симуляции позволяют реализовать и то, и другое.
Искусственные аналоги естественных когнитивных процессов могут быть использованы для реализации соответствующих когнитивных процессов в искусственном интеллекте. Когнитивисты используют биологически правдоподобные модели для воссоздания и объяснения работы мозга человека или животного, их когнитивных функций. Ученые, занимающиеся исследованиями в направлении искусственного интеллекта не ограничены в выборе вычислительных моделей. Отсутствие ограничений – это одновременно и плюс, и минус, ведь, с одной стороны, оно предоставляет больше возможностей для поиска решения конкретной проблемы, а с другой – делает отбор хороших и пригодных для практического применения решений более сложным.

Разница заключается в том, что первые обмениваются вещественными числами, а вторые – спайками (единичными событиями, которые происходят в каждый конкретный момент времени). ANN обучаются с помощью градиентного спуска с алгоритмом обратного распространения ошибки, тогда как как SNN либо таким же методом (когда ML-специалисты пытаются использовать их для решения своих задач), либо по правилу Хебба (Spike timing-dependent plasticity, STDP).






