 Марат Хамадеев
Марат Хамадеев
Гауссовы смеси помогли улучшить выучивание представлений для объектов сцены
Использование нейросетей привело к бурному прогрессу в области машинного зрения и иных направлениях, где требуется сегментировать объекты на каком-то сложном массиве данных, например, двумерном изображении. Сегодня для этого используют многослойные свёрточные сети, в которых по мере увеличения номера слоя растёт и уровень абстракции: от простых границ до целых объектов. Выучивание хороших представлений для последних является главной целью моделей с объектно-центричной архитектурой (object-centric architectures).
Важным этапом на пути к объектно-центричным представлениям изображений является кластеризация выученных признаков так, чтобы они соответствовали одному объекту. Наиболее эффективным способом сделать это принято считать метод Slot Attention (SA), который сопоставляет вектору признаков, сформированным свёрточным энкодером, фиксированное число выходных векторов, называемых слотами (slots). Обучение такой модели приводит к тому, что каждому объекту сцены назначается определенный слот, при этом, если объектов мало, часть слотов останется пустыми.
С алгоритмической точки зрения кластеризацию, выполняемую в методе SA, можно рассматривать как вариацию мягкого метода k-средних с выучиванием рекуррентной функции с помощью управляемого рекуррентного блока (GRU) и многослойного перцептрона (MLP). Однако, это далеко не единственный и не всегда самый оптимальный алгоритм кластеризации. Команда исследователей из AIRI, ФИЦ ИУ РАН и МФТИ предложила при выучивании слотовых представлений объектов сцены заменить метод k-средних на метод модели гауссовых смесей.
По идее авторов, в таком подходе слоты формируются не только на основе центров кластеров, но также и с помощью расстоянии между кластерами и присвоенными векторами слота, что приводит к их более выразительному представлению. Новая модель получила название модуля слотовых смесей (Slot Mixture Module, SMM).
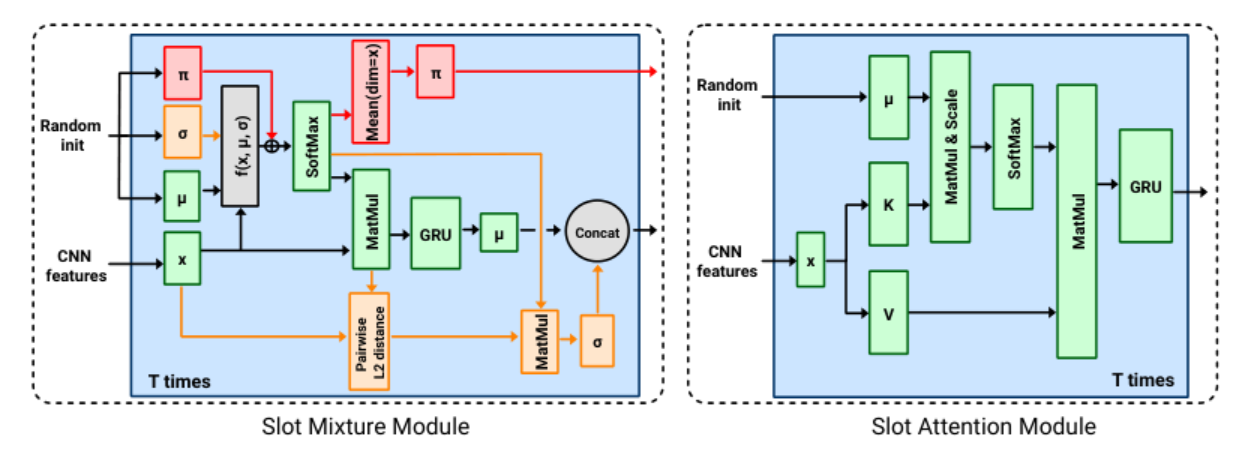
Для проверки эффективности предложенного нововведения команда провела серию экспериментов, сравнивая подход SA и эквивалентный ему SMM на одних и тех же энкодерах и датасетах в широком ряде задач: реконструкция изображений, предсказание свойств множеств, обнаружение объектов, сэмплирование концептов. Также авторы сравнивались с чистыми методами кластеризации — k-средними и гауссовыми смесями, соответственно, — отключая в обоих слотовых подходах GRU и MLP. Эксперименты показали, что использование SMM вместо SA улучшает производительность в объектно-центричных задачах, достигая SOTA-результата на предсказании свойств множества и даже обогоняя специализированную модель.
Исследование было представлено на конференции ICLR 2024, статья опубликована в сборнике её трудов.






