 Марат Хамадеев
Марат Хамадеев
Информация о ближайших соседях помогла точнее дополнять графы знаний
Графы знаний — это способ организации структурированной информации, при котором сущностям ставятся в соответствие вершины некоторого мультиреляционного графа, а их отношениям друг с другом — его рёбра. Можно сказать, что такой граф состоит из набора триплетов: «объект (object, head entity) – отношение (relation) – субъект (subject, tail entity)». Например, утверждению о том, что Стив Джобс родился в Сан-Франциско, соответствует триплет «Стив Джобс» — «родился в» — «Сан-Франциско».
Такая структура обуславливает широкое применение графов знания в самых разных областях: интеллектуальный анализ данных, поиск информации, вопросно-ответные системы и системы рекомендаций. Однако, графы, в которые организована информация о реальных объектах или явлениях, очень часто страдают от пропущенных связей и фактов. В приведённом выше примере система знает о месте рождении Джобса, но место его смерти ей может быть неизвестно.
Решить эту проблему призваны алгоритмы дополнения графа знаний, которые традиционно опираются на выучивание его эмбеддингов, то есть числовых представлений вершин графа. Обученная модель собирает структурную и семантическую информацию о вершинах и рёбрах графа, что позволяет ей выдавать ответ, ориентируясь на критерии близости.
Сейчас активно развиваются методы дополнения графов знаний, использующие языковые модели. Одним из преимуществ в частности, является их способность использовать семантическую информацию, содержащейся в вершинах и рёбрах, а также работать с новыми сущностями и связями, которых не было в графе во время обучения. Такие подходы, как KG-BERT, KGT5 и другие рассматривают триплеты как текстовую последовательность и генерируют ответ, ориентируясь на параметры самой языковой модели.
Исследователи из МФТИ, AIRI и Лондонского института Математических Наук предложили учитывать при этом ближайшие окрестности вершин графа. Согласно их идее, включение в алгоритм информации о соседних вершинах и связях способно улучшить точность дополнения графа. Авторы доказали эту гипотезу для нескольких популярных языковых моделей, как в трансдуктивной, так и в индуктивной постановке задачи.
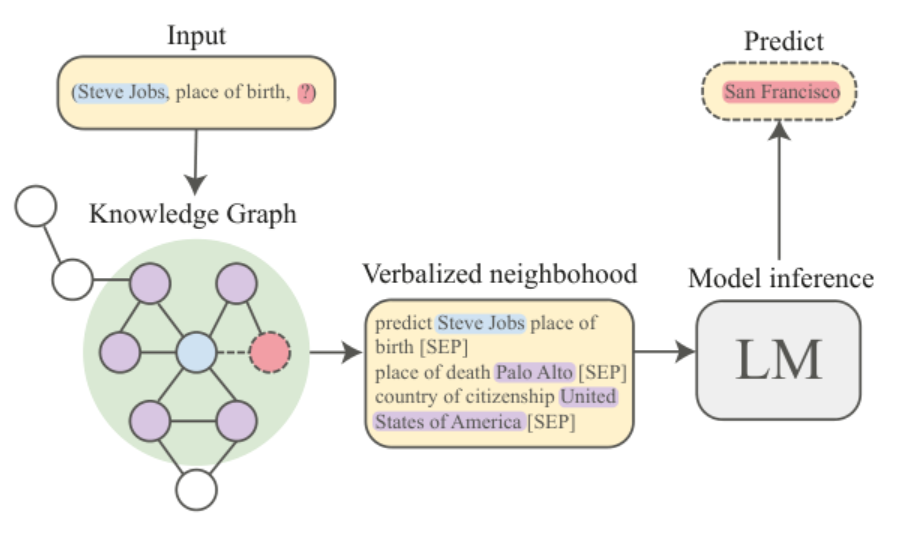
Дополнение графа знаний (например, ответ на фактологический вопрос) представляет собой предсказание правильного субъекта (tail entity, красный кружок), связанного с объектом (head entity), содержащимся в вопросе (синий кружок). Основная идея работы заключается во включении в алгоритм предсказания информации об окрестности (зелёная область), где расположены ближайшие вершины (фиолетовые кружки).
Для экспериментов учёные использовали два поднабора из графа знаний о реальных сущностях Wikidata. Первый из них — Wikidata5M — является одним из самых больших среди общедоступных трансдуктивных (то есть с одинаковым набором сущностей и отношений во время обучения и во время тестирования модели) графов знаний. Второй поднабор представляет собой большую и малую версии датасета ILPC — самого большого среди индуктивных (в них обучение происходит на одном подграфе, а модель тестируется на другом подграфе с новыми вершинами) бенчмарков.
Эксперименты на указанных графах показали, что включение соседних вершин позволяет улучшить качество дополнения графов как для языковых моделей с открытым исходным кодом вроде T5, так и для проприетарных моделей, таких, как GPT от OpenAI. Исследователи смогли показать лучший результат на наборе данных ILPC среди опубликованных на тот момент. На наборе данных Wikidata5M новый подход превзошёл другие генеративные модели дополнения графов и показал результаты, сопоставимые с передовыми методами, использующими графы и языковые модели, несмотря на значительно меньшее количество параметров. В будущем учёные планируют проверить обнаруженных эффект в зависимости от размера модели, а также поработать над стратегиями отбора вершин графа из окрестности и с графами знаний из других доменов.
Подробности исследования можно найти в статье, опубликованной в сборнике трудов конференции EMNLP 2023, а весь код доступен в открытом репозитории. Примечательно, что эта научная работа началась как проект одного из её авторов, Аллы Чепуровой, когда она была студентом на летней школе «Лето с AIRI» в 2022 году.






