 Марат Хамадеев
Марат Хамадеев
Рекуррентная память убрала ограничения на длину входных последовательностей для трансформеров
Обработка естественного языка сегодня немыслима без применений трансформерных моделей. В отличие от рекуррентных нейронных сетей, которые решали подобные задачи до появления трансформеров, последние полагаются исключительно на механизм внимания, который позволяет учитывать контекст, например, окружение отдельного слова в предложении. Избавление от рекуррентности привело к качественному скачку точности и производительности языковых моделей.
Предложение как последовательность символов, подаваемая на вход нейронной сети, разбивается на токены, каждый из которых кодирует слово или его часть. Формально входная последовательность может быть сколь угодно длинной, однако обслуживание механизма внимания приводит к квадратичному росту сложности вычисления. Из-за этого использование больших языковых SOTA-моделей при работе со слишком длинными последовательностями сильно затруднено. Даже в стандартной модели GPT-3.5 Turbo, бесплатно предоставленной OpenAI, эта величина не превышает 16 тысяч токенов.
Конечно, исследователи пытаются преодолеть эту границу различными способами. Так, последняя версия GPT-4 Turbo принимает последовательности длиной до 128 тысяч токенов, а не так давно команда DeepMind отчиталась о том, что их Gemini 1.5 способна учесть контекстное окно в миллион токенов, и тестируются ее возможности на десяти миллионах токенов. Тем не менее, подходы, основанные на стандартном механизме внимания, близки к своему пределу.
По этой причине множество научных групп пытаются найти способ, как снизить вычислительную сложность алгоритмов в трансформерах, чтобы облегчить обработку длинных последовательностей. Одной из них стала команда учёных из МФТИ, AIRI и Лондонского института Математических Наук, которая в последние несколько лет исследует возможность применения памяти для увеличения производительности таких моделей. Под памятью в данном случае понимается несколько выделенных спецтокенов входной последовательности.
В 2022 году исследователи добавили память и рекурретность к уже стандартным трансформерным архитектурам. Для этого они разделили последовательность на сегменты и добавили к входу специальные токены памяти: состояния памяти на выходе предыдущего сегмента становились входными для следующего. Таким образом, целый трансформер выступает в роли рекуррентной ячейки (recurrent cell), а память — рекуррентным состоянием сети. Применение этого подхода, названного рекуррентным трасформером с памятью (Recurrent Memory Transformer, RMT), к различным задачам обработки последовательностей показало его перспективность.
Недавно авторы поделились успехами в применении RMT к нескольким популярным энкодерным и декодерным языковым моделям. В частности, их интересовали пределы возможностей RMT на больших длинах и использование рекуррентной памяти для сокращения вычислительной сложности обработки длинных входных последовательностей. Для этого они аугментировали такой памятью небольшие трансформерные модели BERT и GPT-2, и подвергли их испытанию на нескольких типах вопросно-ответных задач, в которых необходимые для ответа факты находятся где-то в тексте.
Оказалось, что применение рекуррентной памяти позволяет сильно увеличить длину входной последовательности, на которой точность работы нейросети сохраняет удовлетворительное значение. В своих экспериментах учёные смогли довести длину до 2 миллионов токенов. По словам авторов, не существует фундаментальных ограничений на то, чтобы эта величина стала больше, так как вычислительная сложность RMT растёт линейно с числом токенов.
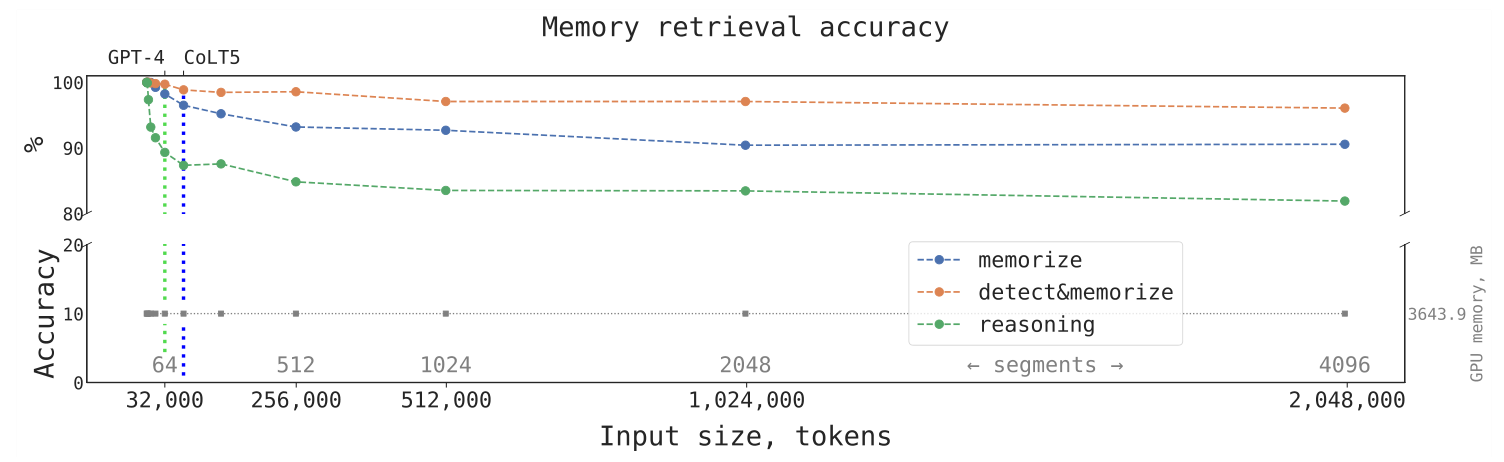
Точность работы предобученной модели BERT, аугментированной RMT, на трёх задачах в зависимости от числа токенов во входной последовательности. Серыми цифрами обозначена потребляемая память GPU, вертикальные линии обозначают лимиты длин в SOTA-моделях (на конец 2023 года).
Сначала мы проводили эксперименты, обучая модель на 7 сегментах (3500 токенов) и оценивая ее качество на длинах до 15 (7500 токенов), но заметили, что качество практически не падало. Тогда мы решили продолжить оценку модели на еще больших длинах. И так дошли сначала до одного миллиона, а затем и до двух миллионов токенов. В целом, этот график можно было бы продолжать и дальше вправо за два миллиона — для этого надо только ждать.

Исследование опубликовано в сборнике трудов конференции AAAI-24, дополнительные детали содержатся в препринте, а код выложен в открытом репозитории.






