Марат Хамадеев
Марат Хамадеев
Два новых подхода улучшили многоагентное планирование пути в децентрализованных условиях
Задача многоагентного планирования пути возникает всякий раз, когда группе агентов требуется перемещаться по общему заданному пространству, чтобы достигать своих целей и при этом не мешать друг другу. С ней приходится сталкиваться при разработке видеоигр, планировании работы курьеров и, конечно же, при автоматизации складов.
Существует множество подходов к решению этой проблемы, однако большинство исследований сконцентрировано вокруг ситуации, когда в системе присутствует некоторый центральный элемент, который обладает полным знанием о среде, местоположении агентов, их целях и так далее и заранее планирует для всех агентов траектории, не содержащие коллизий между ними. На практике системы часто бывают децентрализованными и агенты вынуждены функционировать в условиях частичной наблюдаемости.
Например, агент может обладать знанием только о том, что его окружает. Такие условия требуют постоянного обновления траекторий и классическими символьными методами решить эту задачу довольно сложно. В этой ситуации исследователи возлагают большие надежды на машинное обучение. Такие подходы как Primal2 и SCRIMP уже доказали успешность этой идеи, однако для их обучения требуется большое количество экспертных демонстраций, генерация которых трудозатратна.
Команда исследователей из AIRI и ФИЦ ИУ РАН исследовала несколько путей решения этой проблемы. В основе первого подхода, разработанного ими, лежит поиск по дереву Монте-Карло — один из самых знаменитых подходов в обучении с подкреплением. Так, этот метод лежит в основе программы AlphaGo, которая смогла одолеть чемпиона мира по го в 2016 году. В результате учёным удалось не только отказаться от экспертных демонстраций, но и улучшить качество отыскиваемых решений. Стоит отметить, что в работе рассматривалась постановка задачи, при которой каждому агенту при достижении текущей цели, назначается новая цель. Новый метод получил название Multi-agent Adaptive Tree Search with the Learned Policy (MATS-LP).
Главная сложность применения метода поиска по дереву Монте-Карло к задаче многоагентного планирования пути, заключается в большом числе вариантов в комбинированном пространстве действий, которое доступно агентам в каждом узле дерева. Чтобы его уменьшить, команда добавила в алгоритм выбор только некоторого подмножества агентов, которые могут влиять друг на друга. Для выбора лучшего текущего действия для каждого из агентов учёные использовали предобученную стратегию, которую они назвали CostTracer. Она отвечала за доведение агента до текущей цели, а разрешению конфликтов между агентами помогало планирование по дереву. При этом каждый агент строил своё дерево, что и обеспечивало децентрализованность.
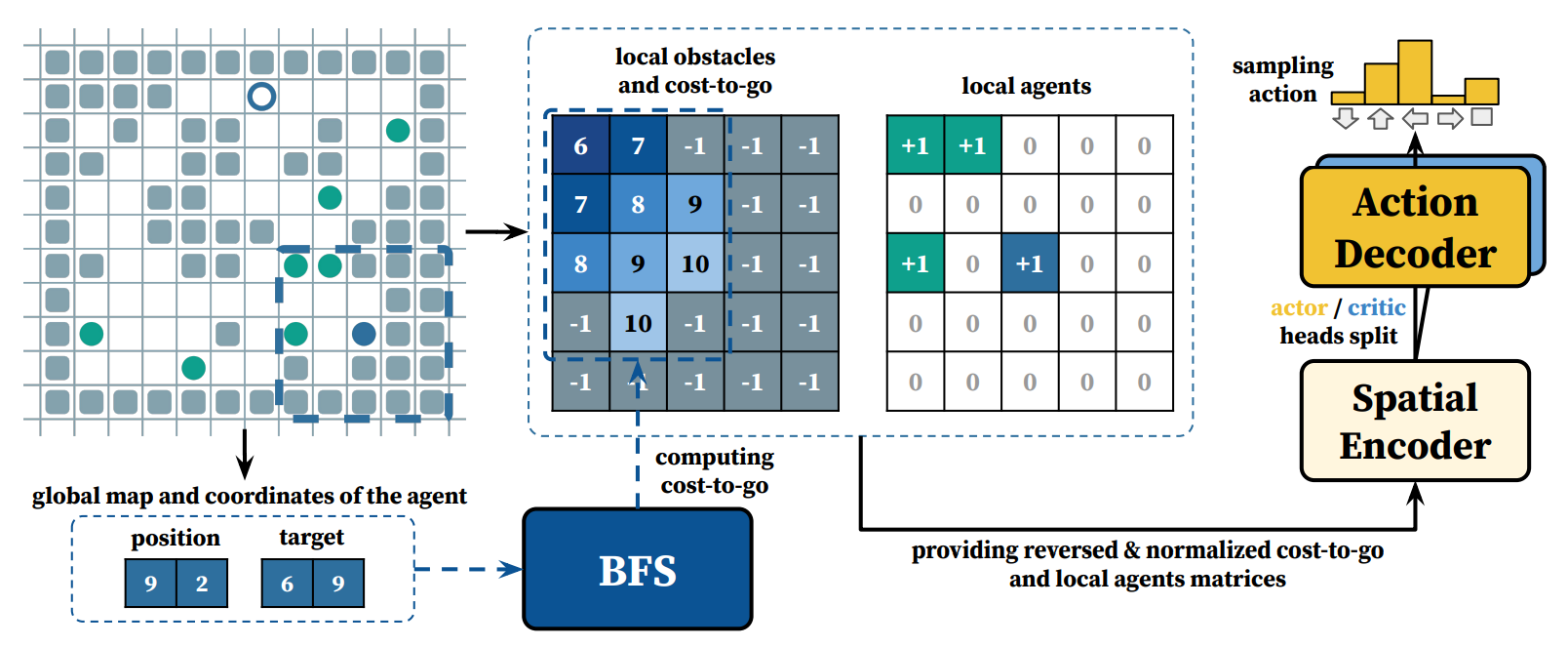
Схема алгоритма CostTracer
Для проверки работоспособности нового подхода авторы провели серию экспериментов на трёх типах сред: картах со случайным распределением препятствий, специальных лабиринтах и карте, имитирующей настоящий склад. Их результаты показали, что предложенный подход позволяет агентам быстрее достигать своих целей по сравнению с аналогами — алгоритмами Primal2 и SCRIMP, причём преимущество тем более существенное, чем больше агентов на карте. Вместе с тем, новый алгоритм оказался способен находить решения для нетривиальных конфликтов.
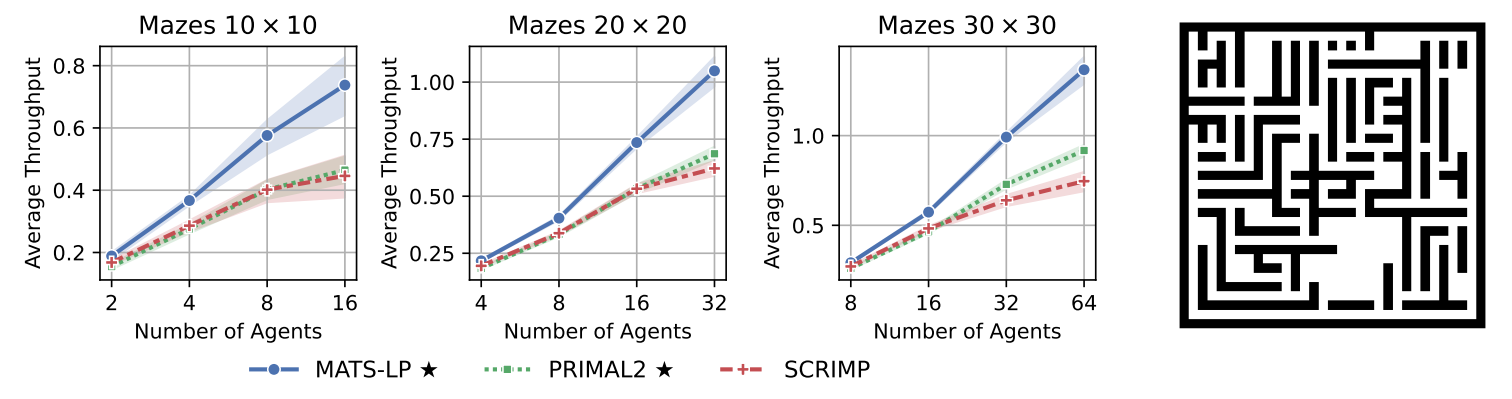
Метрика Average Throughput характеризует количество достигаемых целей всеми агентами за единицу времени. Справа показан пример случайной карты, на которой осуществлялось тестирование алгоритма.
Другой подход к решению задачи многоагентной навигации, к которому обратились исследователи в соавторстве с коллегами из МФТИ, был основан на интеграции алгоритмов обучения с подкреплением и планирования. Алгоритм планирования использует информацию о карте, положении агента и его цели, чтобы построить путь, игнорируя других агентов. Алгоритм же обучения с подкреплением помогает агенту двигаться по этому пути и разрешать конфликты с другими агентами. Этот подход авторы назвали Follower.
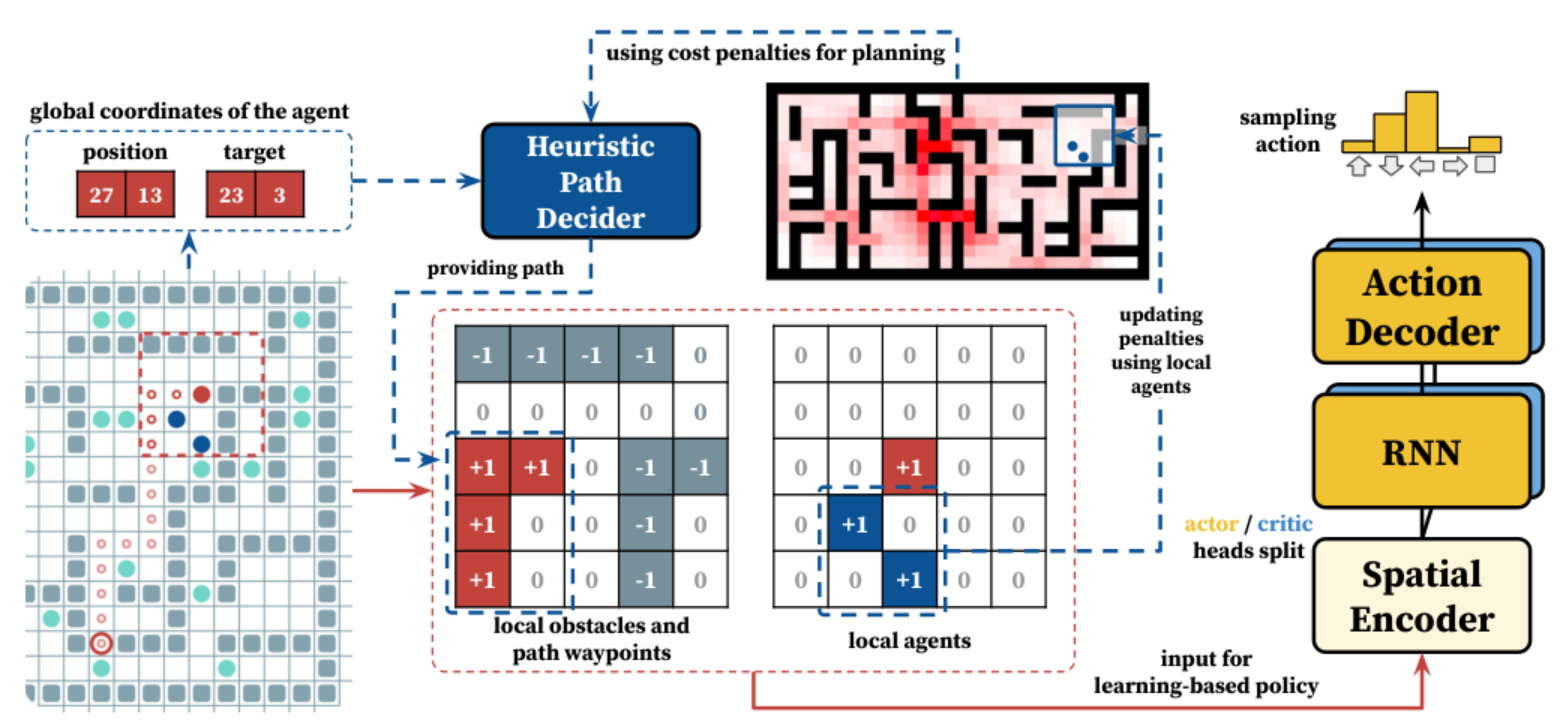
Схема алгоритма Follower
В экспериментах Follower также показал преимущество перед sota-обучаемыми алгоритмами — Primal2, SCRIMP и PICO — в том, сколько целей достигли все агенты. Авторы проводили сравнение на 10 различных лабиринтах и 40 случайных картах с различным числом агентов. Кроме того, они сравнили производительность Follower, а также его облегченной версии FollowerLite c централизованными методами RHCR и PIBT. Оказалось, что благодаря децентрализованному выбору следующего действия каждым из агентов, Follower способен превосходить централизованные методы, как по скорости работы, так и по качеству отыскиваемых решений в случае наличия ограничения по времени на выбор следующего действия для каждого из агентов.
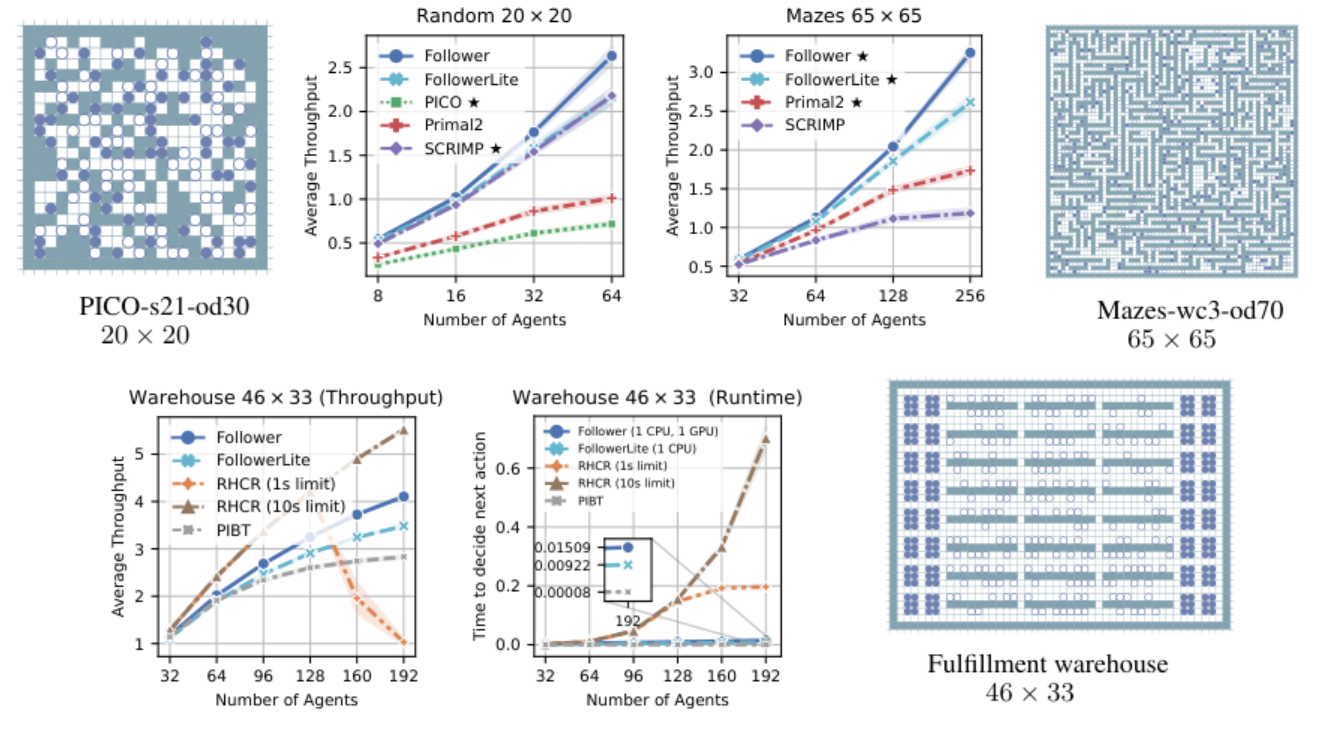
Сверху: сравнение Follower и FollowerLite с обучаемыми алгоритмами по метрике Average Throughput, а также карты, на которых оно проходило. Снизу: сравнение c централизованными методами.
Однозначно можно сказать, что Follower работает значительно быстрее, чем MATS-LP, так как в последнем происходит поиск по дереву. Вместе с тем, всё тот же поиск по дереву позволяет MATS-LP находить решения там, где Follower не справляется.

Результаты своей работы по обоим алгоритмам исследователи представили на конференции AAAI-24. Ознакомиться с её деталями можно по препринтам (MATS-LP и Follower), код проекта доступен на GitHub (MATS-LP и Follower).