Марат Хамадеев
Марат Хамадеев
В трансформерах обнаружили сложную динамику анизотропии и внутренней размерности
Трансформерные модели (трансформеры), предложенные в 2017 году исследователями из Google Brain, совершили революцию как в обработке естественного языка, так и в компьютерном зрении. Особенностью этой архитектуры стал механизм внимания, который хорошо распараллеливается и оперирует эмбеддингами — векторными представлениями фрагментов слов.
По мере роста популярности моделей на базе трансформеров росло и стремление понять тонкости их внутренних механизмов, особенно, что происходит с информацией внутри них. Чтобы пролить свет на этот вопрос, команда исследователей из AIRI, Сбера, Сколтеха, МГУ, ВШЭ и Самарского университета изучила динамику анизотропии и локальных внутренних размерностей промежуточных эмбеддингов в различных трансформерных моделях, в том числе в процессе их обучения.
Анизотропия в данном случае — это мера того, насколько «вытянутым» и неоднородным является пространство эмбеддингов (облако точек в многомерном пространстве). Авторы определяют её с помощью сингулярных чисел центрированной матрицы эмбеддингов и косинусных расстояний между векторами.
Локальная внутренняя размерность, в свою очередь, характеризует форму и сложность, присущие небольшой окрестности пространства точек. Учёные описывали её как скорость, с которой растёт объём многомерной сферы в окрестности точки по мере отдаления от неё.
Команда провела серию экспериментов с несколькими encoder- и decoder-based языковыми моделями, наблюдая за поведением анизотропии и внутренней размерностью на промежуточных слоях на разных этапах обучения. Для получения пространства эмбеддингов был использован датасет enwik8, состоящий из очищенных статей английской Википедии.
В ходе такого исследования эксперты обнаружили несколько интересных закономерностей. Во-первых, для всех декодеров послойный профиль анизотропии выглядит одинаково — на центральных слоях она близка к 1, а в начале и в конце убывает, формируя куполообразную форму. Максимальное значение, в свою очередь, тем больше, чем дольше длится обучение. Данные же в энкодере остаются локально изотропными почти всегда и везде (см. график).
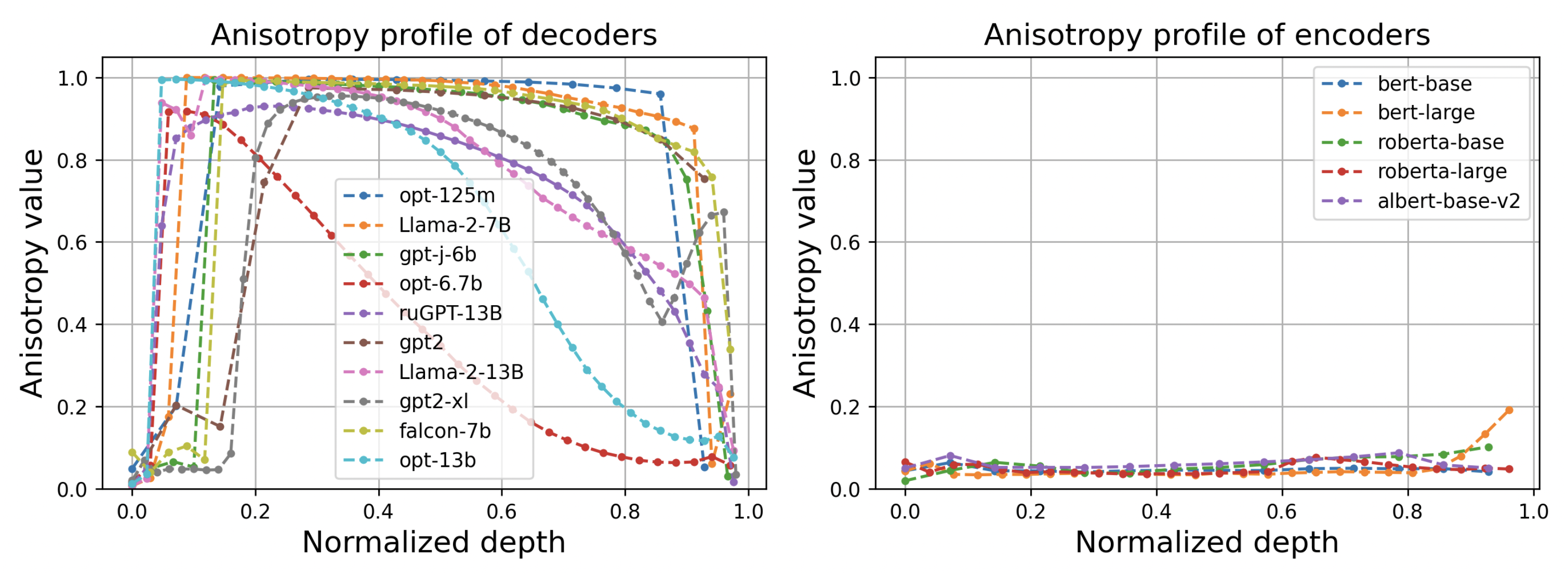
Профиль анизотропии в декодерах и энкодерах различных языковых моделей
Другое открытие было связано с тем, как ведёт себя локальная внутренняя размерность по мере обучения. Оказалось, что на его начальных стадиях наблюдается увеличение размерности репрезентаций, что указывает на попытку модели отобразить информацию в более многомерные пространства. Эта размерность не превышает 60 и с определенного момента начинает почти монотонно снижаться. То есть обучение (претрейн) делится на две фазы — инфляция и компрессия внутренних репрезентаций.
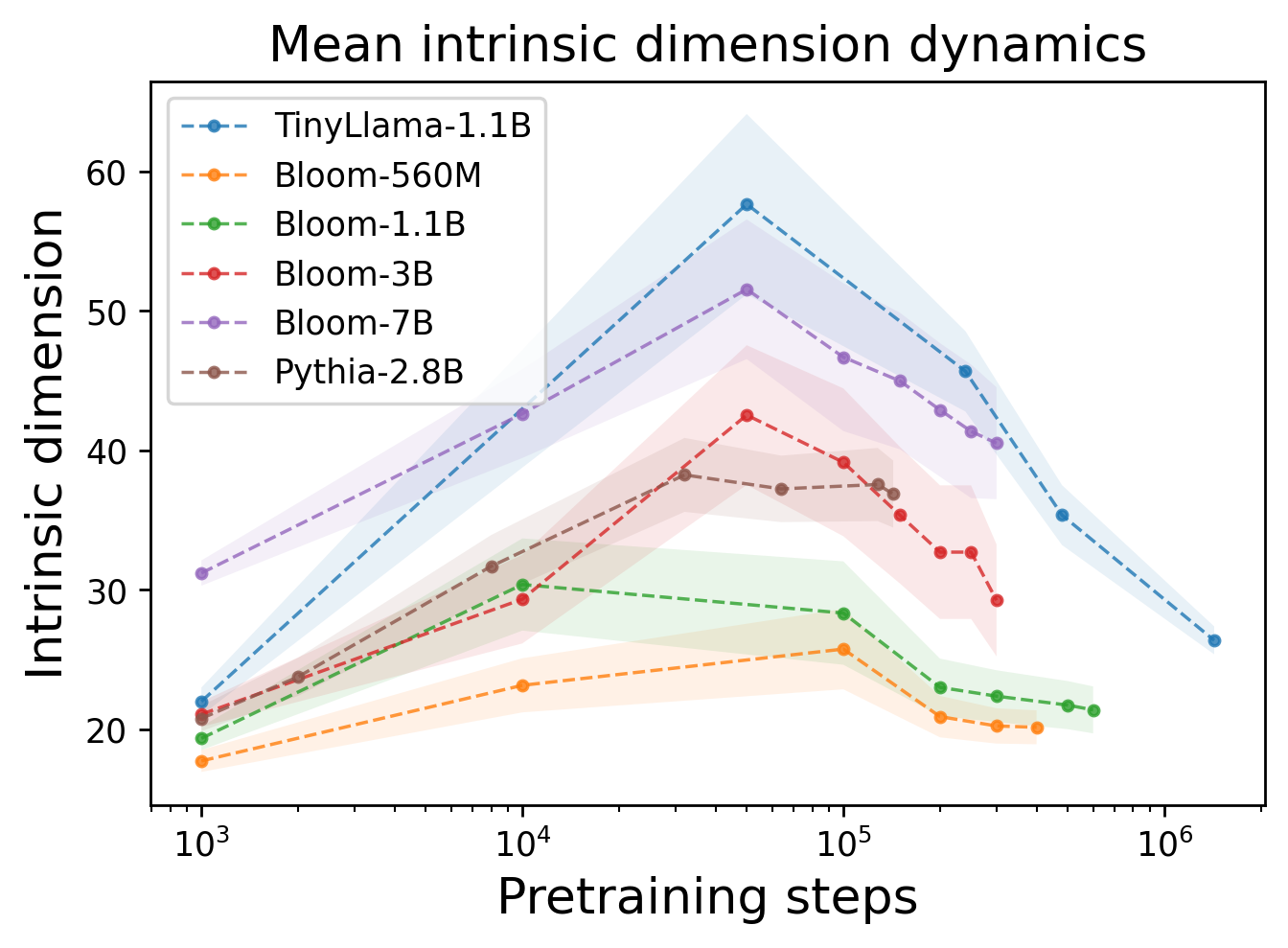
Профиль локальной внутренней размерности для нескольких языковых моделей
Эти открытия углубляют наше понимание трансформерной архитектуры и открывают новые возможности для увеличения эффективности обучения и инференса таких моделей.

Результаты этой работы были представлены на конференции EACL-2024. С её деталями можно ознакомиться по препринту.