Марат Хамадеев
Марат Хамадеев
Новая вопросно-ответная система обошла по точности ChatGPT
За последние несколько лет произошел взрывной рост качества языковых моделей (Language Models, LMs), способных поддерживать запросы на естественном языке. Наиболее известной из них стала ChatGPT, которая приобрела популярность далеко за пределами машинного обучения. Она позволяет пользователям решать самый широкий класс задач, начиная от написания кода и заканчивая переводом текстов.
Однако все большие языковые модели, в том числе и ChatGPT, часто плохо справляются с ответами на фактологические вопросы в том числе из-за того, что их обучающие данные быстро устаревают. Но, если ответ на вопрос четко сформулирован в некоторой регулярно обновляемой базе знаний, например, Википедии, или в локальном графе знаний (Викидата), то для надежной работы таких моделей требуется, чтобы у них был туда постоянный доступ. Наконец, поиск ответа среди миллиардов фактов бывает зачастую довольно сложным.
На решение этих проблем были направлены усилия группы ученых из Сколтеха, AIRI, ИСП РАН и УФУ под руководством Александра Панченко. Они предложили новый метод построения вопросно-ответной системы на графе знаний (Knowledge Graph Question Answering, KGQA), который работает сразу с несколькими языками. В основе этого метода лежит поиск близких сущностей и фактов в пространстве векторных репрезентаций (эмбеддингов) графа. Поскольку граф знаний представляет собой коллекцию триплетов «субъект – предикат – объект», новый метод называется методом многоязычного сопоставления триплетов (multilingual triple match, M3M).
Простыми вопросами принято считать те, в которых явно указан субъект (например, «Как называется столица Великобритании?», субъект здесь — «Великобритания»). В M3M такой вопрос сначала кодируется при помощи энкодера, основанного на базе модели multilingual BERT (mBERT). Репрезентация вопроса — это вектор из 768 чисел, который затем с помощью трёх других небольших моделей отображается в три новых вектора, соответствующих элементам искомого факта-триплета. А ответ находится сопоставлением этих векторов с эмбеддингам из графа знаний.
На роль последнего ученые выбрали многоязычный граф знаний Wikidata, который также опирается на связанные друг с другом статьи из Википедии. Каждая сущность такого графа представляется в виде точки в пространстве эмбеддингов. M3M ранжирует триплеты из графа по близости к искомому триплету с помощью косинусных расстояний, и выбирает самый первый в качестве ответа.
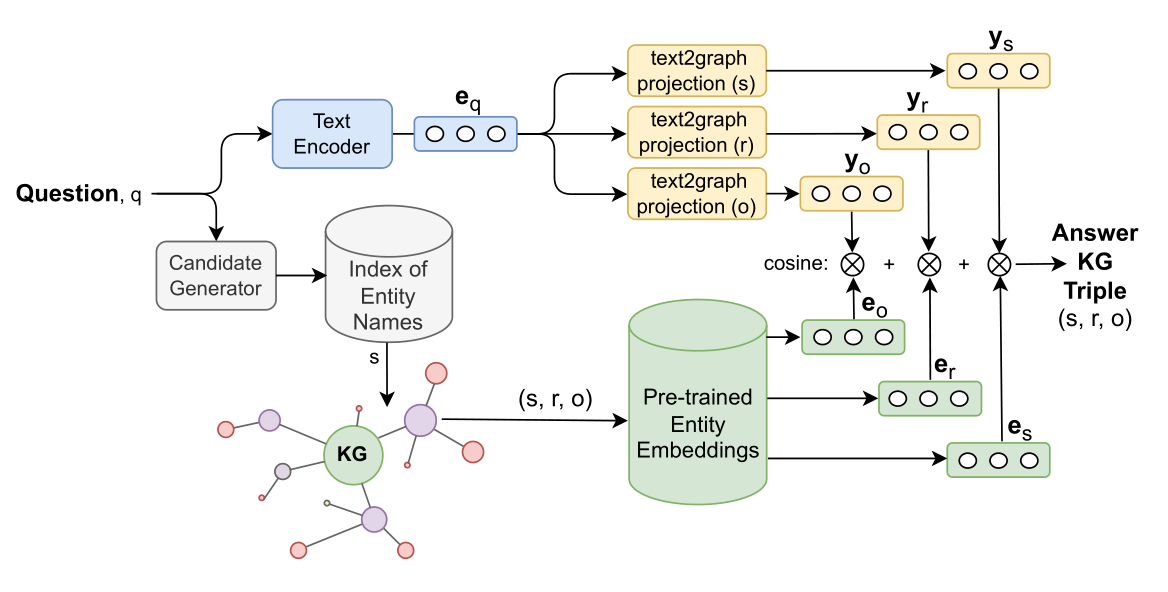
Пайплайн работы системы M3M
Для проверки эффективности работы модели команда взяла несколько датасетов с вопросами (SimpleQuestions, RuBQ, Mintaka-Simple), а также набор специально сконструированных промптов для ChatGTP, чтобы иметь возможность оценить и её возможности. В результате экспериментов ученые выяснили, что M3M точнее отвечает на простые вопросы, чем другие системы, включая различные версии T5, GPT-3, ChatGPT, KEQA и QAnswer. На датасете Mintaka M3M не всегда имела преимущество, но по крайней мере была соизмерима по эффективности с другими моделями.
Остаются задачи, которые простым увеличением размеров моделей решить нельзя, одна из таких задач — это актуализация знаний, ведь «интеллект» языковых моделей отсекается по дате составления их обучающих датасетов. Самым простым решением было бы дать этим моделям доступ в интернет и позволить «гуглить» новую и актуальную информацию — но тогда появляется риск получить недостоверные факты. Думаю, что самый надёжный способ обойти это ограничение — опираться на верифицируемые и постоянно обновляемые графы знаний.

Исследователи выложили код проекта на Github. Больше технических деталей можно найти в статье, опубликованной в сборнике трудов конференции ACL-2023.