 Марат Хамадеев
Марат Хамадеев
Химические языковые модели продемонстрировали плохое знание химии
Применение языковых моделей в химии открыло новые возможности для автоматического анализа свойств веществ, генерации новых соединений и предсказания реакций. Для этого названия молекул, уравнения реакций и другая химическая информация должны быть преобразованы в текстовый вид. Это можно сделать в рамках системы SMILES, системы ИЮПАК или с помощью текстового описания молекул в кросс-доменных моделях.
По такому принципу активно развивается целый ряд современных моделей, например, ChemBERTa или MolT5. Эти модели демонстрируют неплохую производительность на поставленных перед ними химических задачах. Но открытым остаётся вопрос, действительно ли современные языковые модели научились понимать химические законы, или они просто выучивают текстовые представления молекул?
Команда NLP‑исследователей из AIRI и Сбера решила ответить на этот вопрос, создав AMORE — новый и гибкий метод оценки надёжности современных химических языковых моделей. Он подходит как для моделей, обученных исключительно на строковых представлениях молекул, так для обучавшихся на комбинированном корпусе, в котором строковые представления объединены с текстовыми описаниями.
В основе AMORE лежит оценка близости распределённых представлений молекул и их аугментаций. Авторы остановили свой выбор на четырёх аугментациях: канонизации, явном добавлении в запись атомов водорода, кекулизации и перенумерации циклов. Все эти модификации меняют строковое представление, но сохраняют химическую природу молекул. Исследователи провели эксперимент на двух популярных наборах данных: датасете ChEBI-20, который содержит около 3000 пар «молекула-описание», и подмножестве молекул-изомеров из датасета QM9, для которых авторы нашли текстовые описания в PubChem.
Проверка показала, что существующие химические языковые модели неустойчивы даже к простым аугментациям SMILES‑строк, а при использовании аугментированных представлений качество сгенерированных описаний молекул значительно снижалось. Кроме того, в ходе экспериментов обнаружилось, что выбранная метрика изменяется подобно классическим метрикам генерации текста, таким как ROUGE и METEOR.
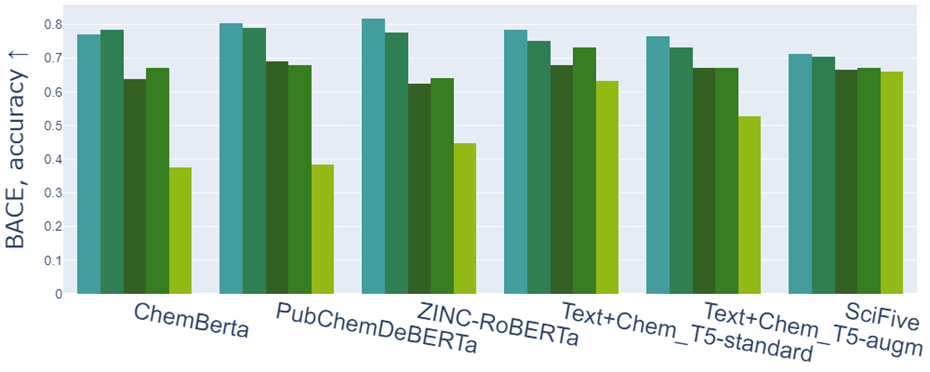
Просадка точностей некоторых моделей на задаче о классификации молекул по способности ингибировать β‑секретазу человека (BACE 1 task). Цветом слева направо закодированы оригинальные данные и их аугментации: перенумерация циклов, канонизация, кекулизация, добавление водорода.
Результаты работы исследователей демонстрируют, что удовлетворительного понимания законов химии в современных химических языковых моделях пока нет.
Статья с описанием метода была опубликована в сборнике трудов конференции EMNLP 2024, код открыт и выложен на GitHub.






