 Татьяна Земскова
Татьяна Земскова
Семантические связи между объектами улучшили понимание 3D-сцены
Важным навыком, которым должны обладать воплощённые агенты (то есть, роботы, беспилотный транспорт и тому подобные устройства), является способность решать задачи на стыке компьютерного зрения и естественного языка. К таким задачам относятся понимание и описание 3D-сцены и генерация ответов на вопросы про неё.
Большие языковые модели (LLMs) хорошо подходят на роль ключевого элемента таких интеллектуальных систем. В этом случае описание трёхмерной сцены тоже может иметь вид текста, однако на практике всё чаще стали использовать различные выучиваемые представления, кодирующие как-либо объекты и отношения между ними, например, с помощью облака точек или графа. В последнем случае узлам графа соответствуют объекты, а рёбрам — их отношения (например, «стул стоит на полу»).
Использование выучиваемых представлений позволяет компактнее задавать сцену и улучшает точность решения задач, но существующие подходы не позволяют учитывать семантические связи между объектами. На этот факт обратила внимание команда исследователей из AIRI и МФТИ, которая предложила новое графовое представление сцены в своем методе 3DGraphLLM.
Главная цель авторов заключалась в том, чтобы показать, что наличие семантических связей между объектами в графе сцены позволяет эффективнее отличать их друг от друга по текстовому описанию, и, следовательно, повышает качество пространственного восприятия 3D-сцены LLM. Для её достижения они предложили организовать представление таким образом, чтобы каждому объекту сопоставлялся подграф, содержащий сам объект и его ближайших соседей. Ключевую роль при этом играет извлечение эмбеддингов семантических отношений между объектами, которое авторы проводили с помощью современного метода VL-SAT.
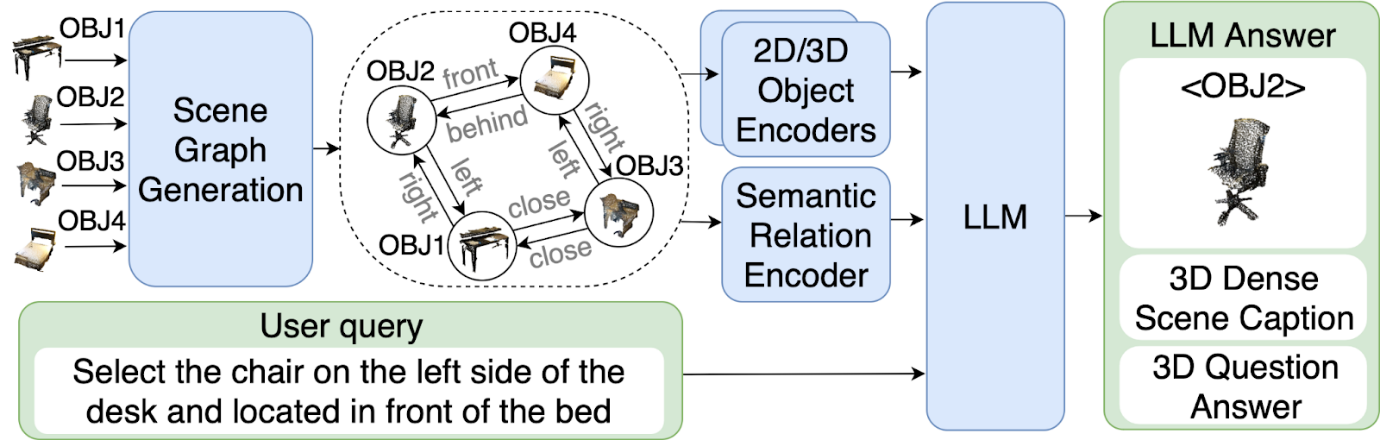
Схема работы подхода 3DGraphLLM
Для проверки преимуществ нового подхода исследователи решали с его помощью несколько задач и сравнивали целевые метрики с существующими методами. В частности, они просили модель находить область в 3D-сцене, соответствующую сложному запросу на естественном языке, и, наоборот, описать объект в заданной пространственной области. Другим типом задач была генерация ответов на вопросы о свойствах сцены.

3DGraphLLM демонстрирует способность к использованию здравого смысла, заложенного в LLM, чтобы решать задачи
Нововведение оказалось наиболее эффективным при решении задачи 3D-детекции по текстовому запросу, но в остальных задачах исследователи также зафиксировали прирост метрик. При этом наилучший баланс между скоростью и качеством решения достигался тогда, когда в подграфе оставалось всего по две связи на объект. В дальнейшем исследователи планируют сократить количество токенов на кодирование связей, добавить автоматический поиск связей, учесть динамические изменения в графе, а также расширить пул решаемых методом задач.
Статья с исследованием принята к публикации в сборнике трудов конференции ICCV 2025, код и веса модели открыты.






