 Марат Хамадеев
Марат Хамадеев
Неизменность вопроса указана на собственные знания языковых моделей
Большие языковые модели (Large language models, LLMs) нашли применение в широком круге задач, включая ответы на вопросы пользователей. Как и во всех остальных приложениях, LLM склонны галлюцинировать, что в данном случае выражается в выдумывании имён, дат, фактов или иных деталей. Другой проблемой при создании вопросно-ответных систем на базе языковых моделей является устаревание информации.
С описанными трудностями сегодня принято справляться с помощью подхода на основе генерации с дополненным поиском (Retrieval-Augmented Generation, RAG). В рамках RAG информация, полученная во внешних источниках (файлы, базы данных, интернет и так далее), включается в контекст языковой модели для генерации итогового ответа.
RAG — это мощный инструмент для повышения надёжности LLM, но на поиск релевантного контекста может уходить довольно много времени. Кроме того, RAG значительно увеличивает размер входной последовательности модели, что в ряде случаев снижает точность ответа для информации, лежащей в середине контекстного окна. Таким образом, перед применением этой техники имеет смысл как-то оценить шансы на то, что модель способна ответить на вопрос с помощью собственных знаний, не запуская её инференс.
Для этого можно анализировать сам вопрос: его длину, количество именованных сущностей и их частотные характеристики и иные признаки. Команда исследователей из Сколтеха, AIRI и MTS AI предложила обратить внимание на то, является ли вопрос неизменным (evergreen) или изменяемым (mutual). Ответы на неизменные вопросы не зависят от времени, места или иного контекста, в которых они задаются (например: «Кто был первым президентом США?»). В противовес им ответы на изменяемые вопросы могут быть разными в разное время или в различных условиях (например: «Кто является президентом США?»).
LLM часто испытывают трудности с изменяемыми вопросами, потому что во время предобучения они видят текст, где президентами называют разных людей. Поэтому на вопрос о том, кто сейчас управляет Соединёнными Штатами, не всегда однозначен. Вместе с тем, со вторым типом вопросов языковые модели справляются отлично. Таким образом, если вопрос неизменный, например, касающийся каких-либо исторических фактов, то в большинстве случаев LLM правильно ответит на вопрос на основе собственных знаний, и запускать RAG-пайплайн не имеет смысла.
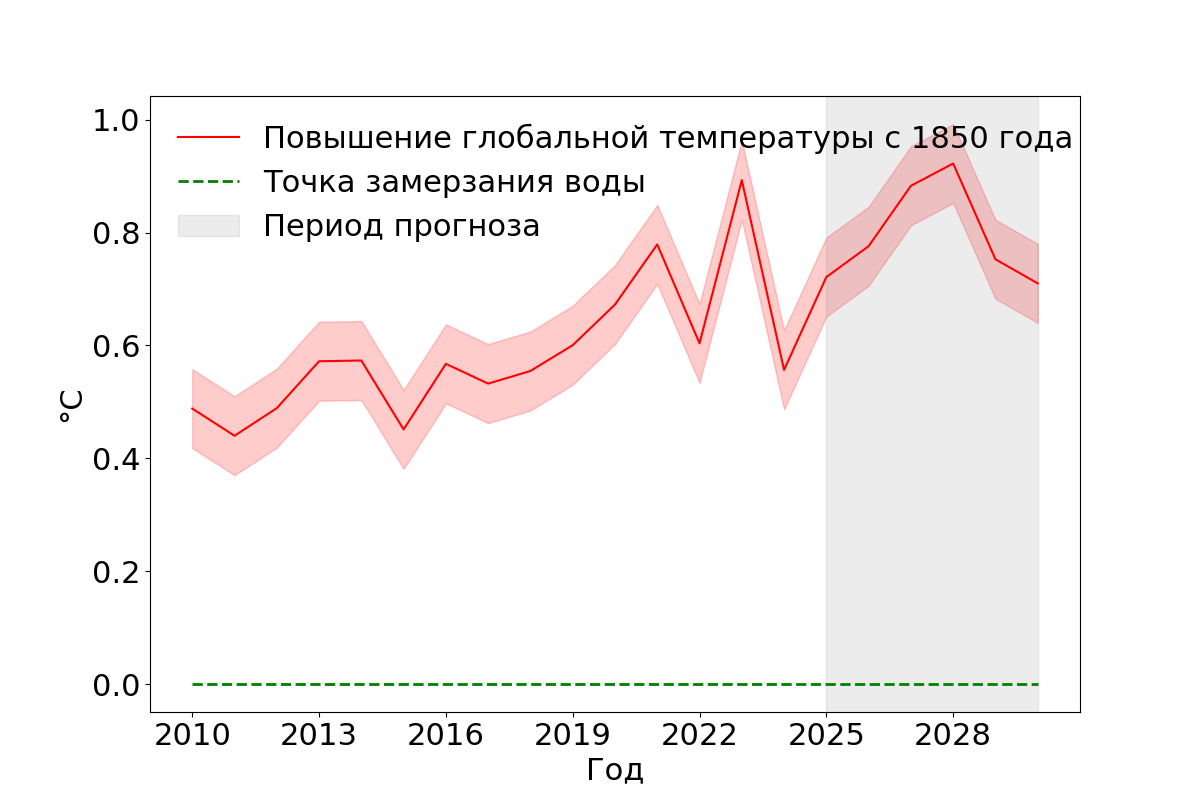
Вопрос о том, чему равна температура замерзания воды в нормальных условиях, является неизменным (зеленая линия). Вопрос же о приросте средней глобальной температуры относится к изменяемым (красная линия).
Чтобы оценить, как тип вопроса влияет на шансы, что модель справится с ответом без RAG, авторы собрали датасет EverGreenQA, который состоит из 4757 вопросов на 7 языках, включая русский, и вручную разметили их по критерию изменяемости. С помощью датасета они разработали классификатор EverGreen-E5, который работает точнее всех существующих LLM даже в режиме few-shot.
Далее исследователи применили классификатор для оценки собственных знаний нескольких популярных языковых моделей, сравнив его с прочими метриками неопределённостей. Оказалось, что учёт неизменности вопросов помогает точнее оценивать знания моделей, хотя этот эффект оказался разным в зависимости от моделей. В частности, если вопрос неизменный, то LLM, вероятно, знает на него ответ. В противном случае модели может быть как правильный, так и неправильный. Также команда выяснила, что этот фактор оказался лучшим предиктором поискового поведения у закрытой модели GPT-4o.
Больше деталей можно найти в научной статье. Датасет и код классификатора находятся в открытом доступе на Huggingface.






