Marat Khamadeev
Marat Khamadeev
Two new approaches accelerated Multi-agent Pathfinding in decentralized settings
The task of Multi-agent Pathfinding (MAPF) arises whenever a group of agents needs to move through a graph to achieve their goals without obstructing each other. This is encountered in the building of automated warehouses, development of video games, intelligent transport systems, etc.
There are many approaches to solving this problem, but most research is focused on situations where there is a central element in the system that has complete knowledge of the environment, agent locations, goals, etc., and plans collision-free trajectories for all agents. In practice, systems are often decentralized, and agents operate under conditions of partial observability.
For example, an agent may have access to only local observation. Such conditions require constant trajectory updates, and solving this problem with classical symbolic methods is quite challenging. One of the possible alternative ways is to utilize machine learning. Approaches like Primal2 and SCRIMP have already shown the success of this idea, but they require a large number of expert demonstrations for training, which can be hard to generate.
A team of AIRI and FRC CSC RAS researchers explored several ways to address this problem. The first approach they developed is based on Monte Carlo Tree Search — one of the most famous approaches in reinforcement learning. This method underlies the AlphaGo program, which defeated the world champion in Go in 2016. The researchers were able to not only eliminate the need for expert demonstrations but also improve the quality of the solutions found. In their work so-called Lifelong variant of the MAPF problem was considered, which involved assigning a new goal to each agent upon reaching the current one. The new method was named Multi-agent Adaptive Tree Search with the Learned Policy (MATS-LP).
The main challenge in applying the Monte Carlo Tree Search method to the Multi-agent Pathfinding problem lies in the large number of alternatives in the combined action space available to agents at each tree node. To reduce this, the team added to the algorithm the selection of only a subset of agents that can influence each other. To choose the best current action for each agent, the researchers used a pre-trained strategy called CostTracer. It was responsible for guiding the agent to the current goal, while conflict resolution between agents was aided by tree planning. Each agent built its tree, ensuring decentralization.
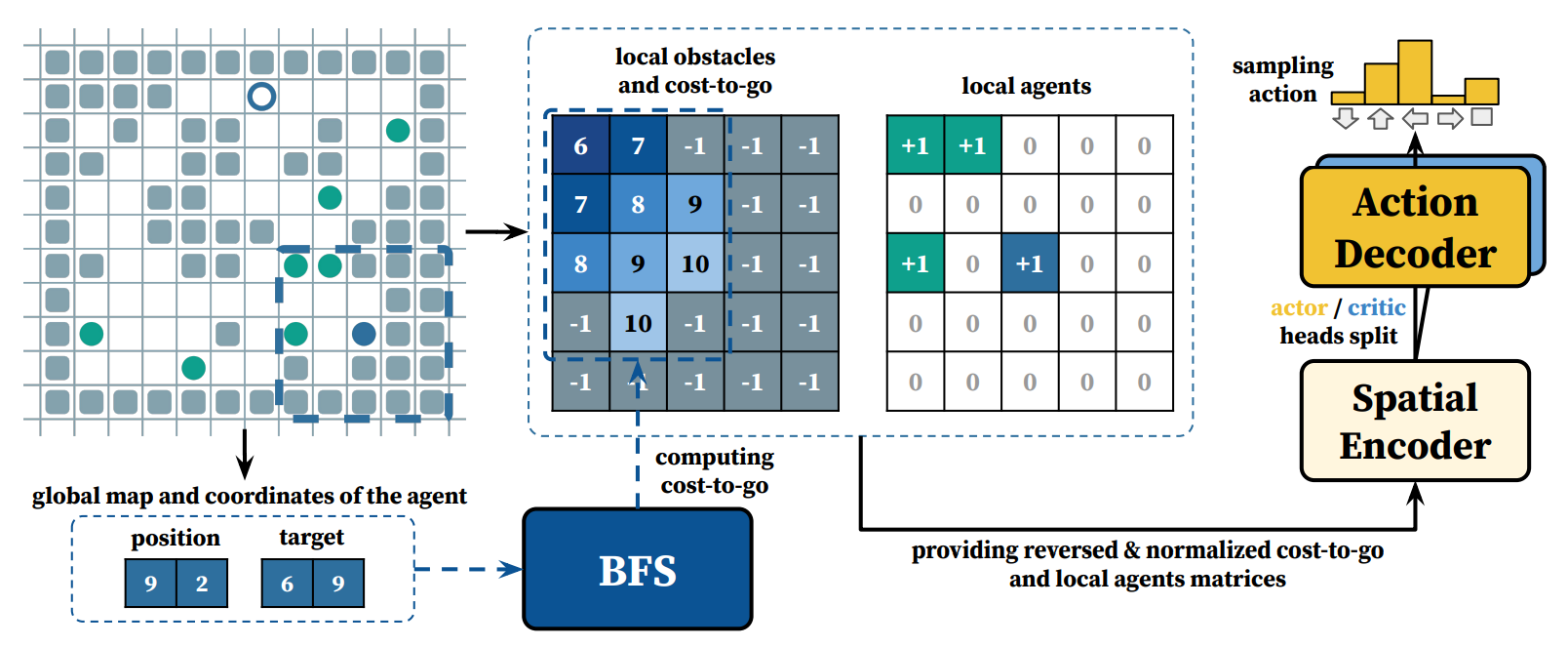
The pipeline of CostTracer algorithm
To test the effectiveness of the new approach, the authors conducted a series of experiments in three types of environments: maps with randomly placed obstacles, maze-like maps, and a warehouse map. Their results showed that the proposed approach allows agents to reach their goals faster compared to counterparts — the Primal2 and SCRIMP algorithms, with the advantage becoming more significant as the number of agents on the map increases. Additionally, the new algorithm proved capable of finding solutions for non-trivial conflicts.
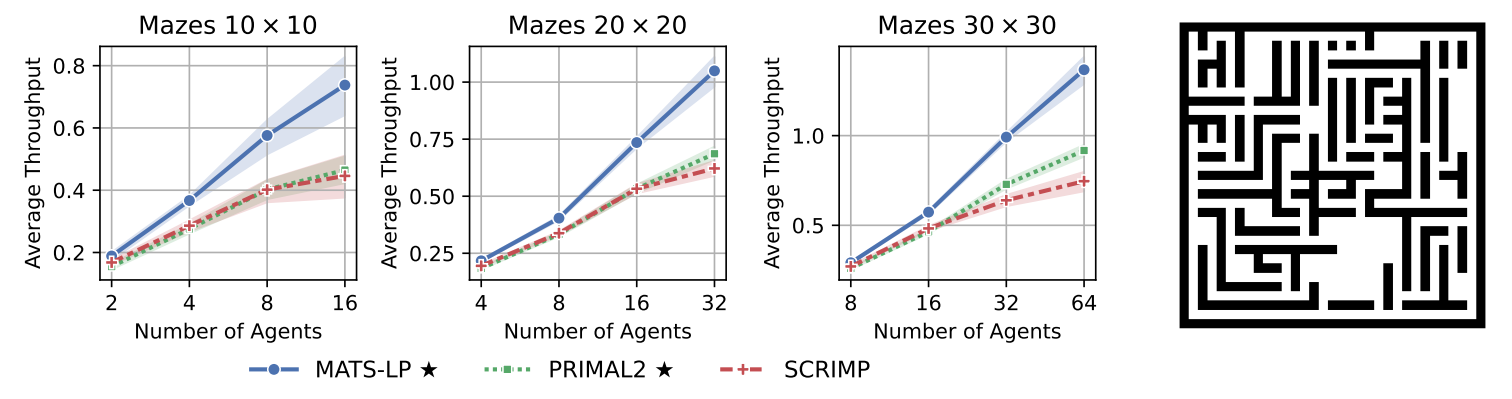
The Average Throughput metric is the average number of goals the agents achieve per one-time step. On the right is an example of a random map on which the algorithm was tested.
Another approach to solving the multi-agent navigation problem that the researchers explored in coauthorship with colleagues fr om MIPT was based on integrating reinforcement learning with path-planning algorithms. The planning algorithm uses information about the map, the agent's position, and the goal to construct a path, ignoring other agents. Reinforcement learning helps the agent move along this path and resolve conflicts with other agents. The authors called this approach Follower.
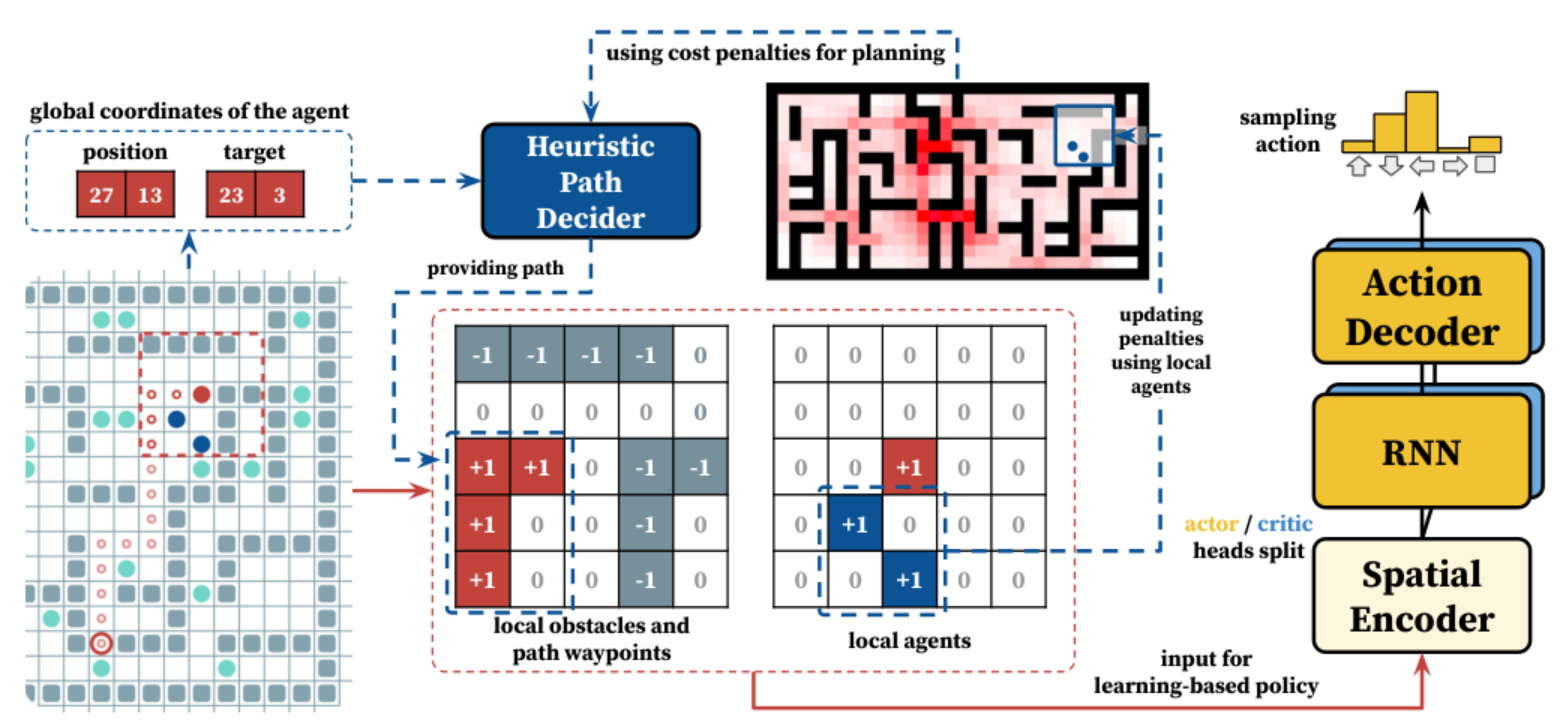
The pipeline of Follower algorithm
In experiments, Follower also demonstrated an advantage over state-of-the-art learnable methods — Primal2, SCRIMP, and PICO. The authors conducted comparisons on 10 different mazes and 40 random maps with varying numbers of agents. They also compared the performance of Follower and its lightweight version FollowerLite with centralized methods RHCR and PIBT. It turned out that due to the decentralized choice of the next action by each agent, Follower is capable of outperforming centralized methods both in terms of speed and quality of solutions found when the time for choosing the next action for each agent is limited.
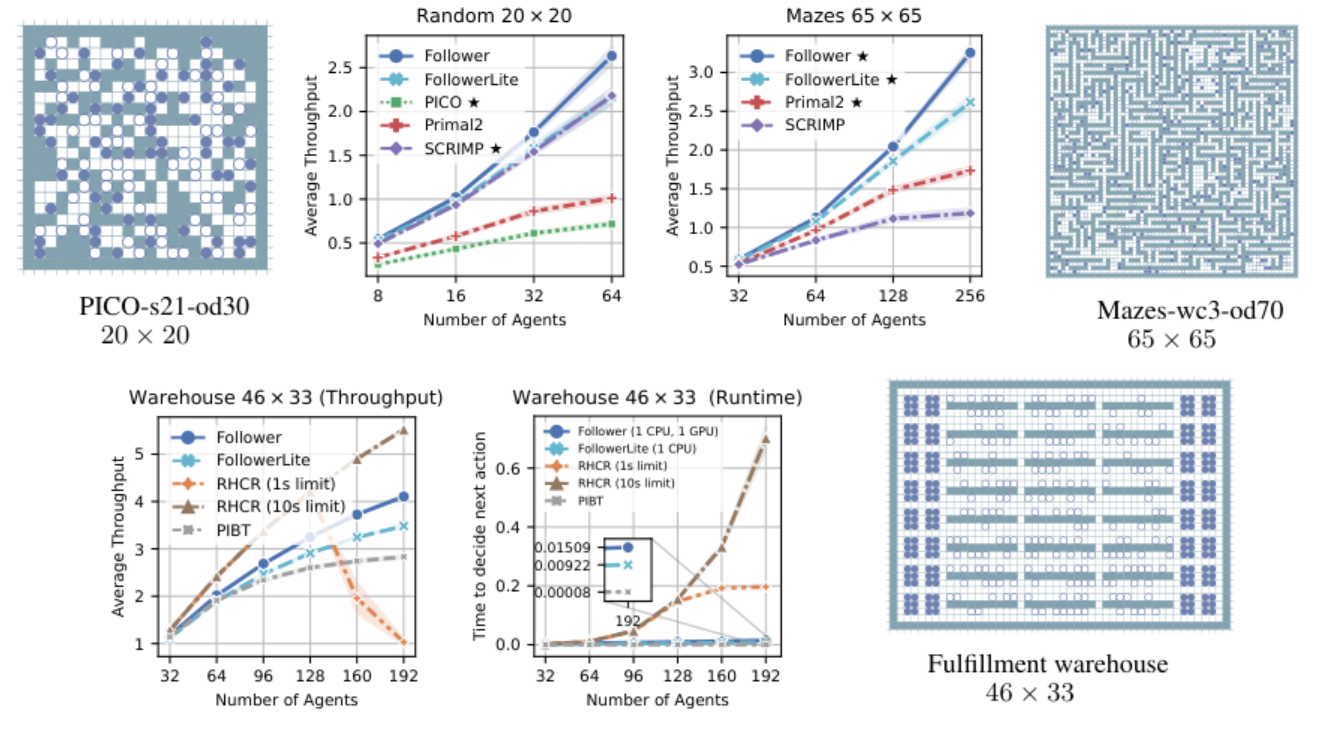
Top: comparison of Follower and FollowerLite with learnable algorithms using the Average Throughput metric, as well as the maps on which it took place. Bottom: comparison with centralized methods.
It can be stated that Follower works significantly faster than MATS-LP since the latter involves tree search. However, the same tree search capability allows MATS-LP to find solutions wh ere Follower fails.

The researchers presented the results of their work on both algorithms at the AAAI-24 conference. Details can be found in the preprints (MATS-LP and Follower), and the project code is available on GitHub (MATS-LP and Follower).