 Marat Khamadeev
Marat Khamadeev
Recurrent memory removed restrictions on the length of input sequences for transformers
Today, natural language processing is unthinkable without the use of transformer models. Unlike recurrent neural networks, which solved similar tasks before the emergence of transformers, the latter rely solely on attention mechanisms, which allow them to consider context, such as the surroundings of an individual word in a sentence. Getting rid of recurrence led to a qualitative leap in the accuracy and performance of language models.
A sentence, as a sequence of characters fed into a neural network, is divided into tokens, each of which encodes a word or its part. Formally, the input sequence can be of any length, but servicing the attention mechanism leads to a quadratic growth in computational complexity. This makes it challenging to use state-of-the-art large language models when working with excessively long sequences. Even in the standard GPT-3.5 Turbo model provided for free by OpenAI, this value does not exceed 16 thousand tokens.
Researchers are trying to overcome this limitation in various ways. For example, the latest version of GPT-4 Turbo can handle sequences up to 128 thousand tokens in length, and not long ago, the DeepMind team reported that their Gemini 1.5 model can consider a contextual window of a million tokens and is being tested on sequences of ten million tokens. However, approaches based on the standard attention mechanism are approaching their limit.
For this reason, many research groups are trying to find ways to reduce the computational complexity of transformer algorithms to facilitate the processing of long sequences. One such group is a team of scientists from MIPT, AIRI, and the London Institute of Mathematical Sciences, who have been researching the use of memory to improve the performance of such models in recent years. In this case, the memory is several special tokens in the input sequence.
In 2022, researchers added memory and recurrence to standard transformer architectures. They segmented the sequence and added special memory tokens to the input: memory states from the output of the previous segment became inputs for the next one. Thus, a whole transformer acts as a recurrent cell, and memory serves as the recurrent state of the network. Applying this approach, called Recurrent Memory Transformer (RMT), to various sequence processing tasks has shown promise.
The authors recently shared successes in applying RMT to several popular encoder and decoder language models. Specifically, they were interested in using recurrent memory to reduce the computational complexity of processing long input sequences. They augmented small transformer models like BERT and GPT-2 with this memory and tested them on various question-answering tasks where facts needed for answering are somewhere in the text.
It was found that using recurrent memory significantly increases the length of the input sequence while maintaining satisfactory neural network performance accuracy. In their experiments, scientists were able to extend this value to 2 million tokens. According to the authors, there are no fundamental limitations for this value to increase further, as the computational complexity of RMT grows linearly with the number of tokens.
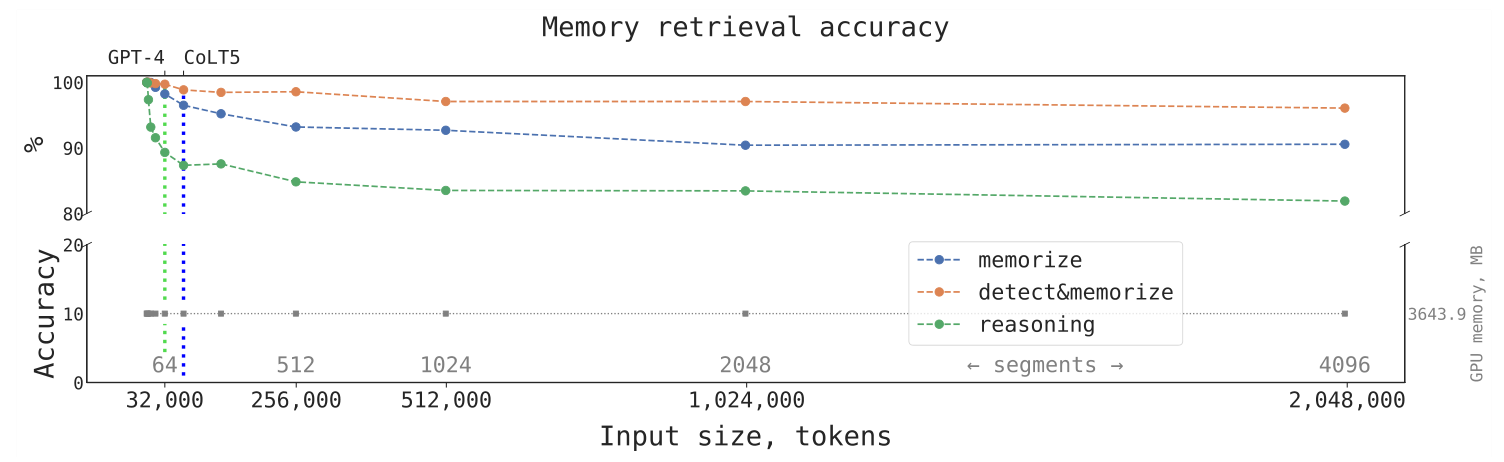
The accuracy of the pre-trained BERT model augmented with RMT on three tasks vs the number of tokens in the input sequence. The gray numbers indicate the GPU memory consumption, and the vertical lines represent the length limits in SOTA models (as of the end of 2023).
The research was published in the proceedings of the AAAI-24 conference, additional details are provided in the preprint, and the code is available in an open repository.






