Marat Khamadeev
Marat Khamadeev
Complex dynamics of anisotropy and intrinsic dimensions have been discovered in transformers
Transformer-based models (transformers), proposed in 2017 by Google Brain researchers, revolutionized both natural language processing and computer vision. The key feature of this architecture is the attention mechanism, which operates well with embeddings — vector representations of word fragments.
As the popularity of transformer-based models grew, so did the pursuit to understand the intricacies of their internal mechanisms, particularly in the realm of embeddings. To shed light on this issue, a team of researchers from AIRI, Sber, Skoltech, MSU, HSE, and Samara University studied the dynamics of anisotropy and local intrinsic dimensions of intermediate embeddings in various transformer models, including the ones during their training process.
In this case, anisotropy is a measure of how “stretched” and heterogeneous the space of embeddings is (a point cloud in a multi-dimensional space). The authors define it using singular values of the centered matrix of embeddings and cosine distances between vectors.
Local intrinsic dimension, in turn, characterizes the shape and complexity that are inherent in a small neighborhood of point space. Scientists described it as a speed at which the volume of a multi-dimensional sphere grows around the point as one moves away from it.
The team conducted a series of experiments with several encoder- and decoder-based language models, monitoring the behavior of anisotropy and intrinsic dimension in the middle layers at various stages of training. The embedding space was obtained using the enwik8 dataset, consisting of cleaned articles from English Wikipedia.
During the study, experts discovered several interesting patterns. Firstly and foremost, for all decoders, the layer-by-layer anisotropy profile looks the same — it is close to 1 at the central layers, and at the beginning and the end, it decreases forming a bell-shaped curve. The maximum value, in turn, grows as the time of the training increases further. The data in the encoder remains locally isotropic almost always and everywhere (see figures below).
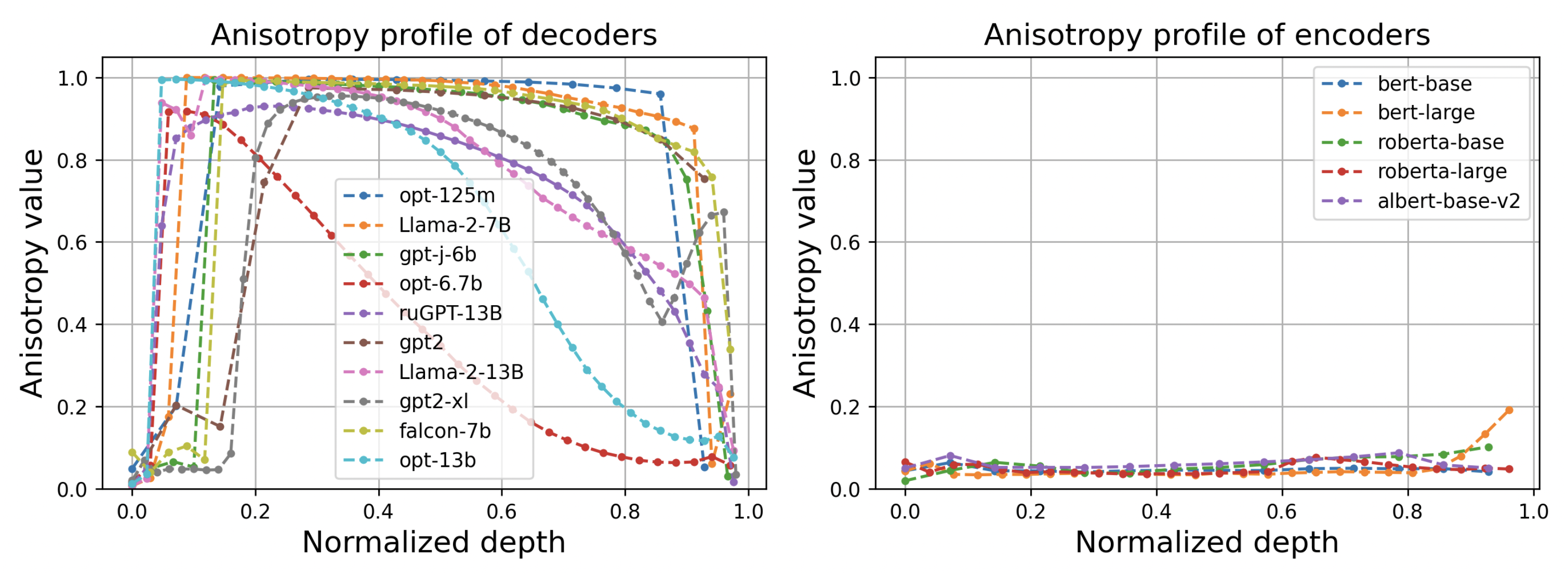
Anisotropy profile in decoders and encoders of various language models
Another discovery was related to the way the local intrinsic dimension behaves during training. It turned out that there is an increasing dimensionality of representations, indicating the model’s attempt to map the information into higher dimensional spaces, in its initial stages. This dimension does not exceed 60 and begins to gradually decrease almost monotonically from a certain point. Therefore, training (pretrain) is divided into two phases — inflation and compression of internal representations.
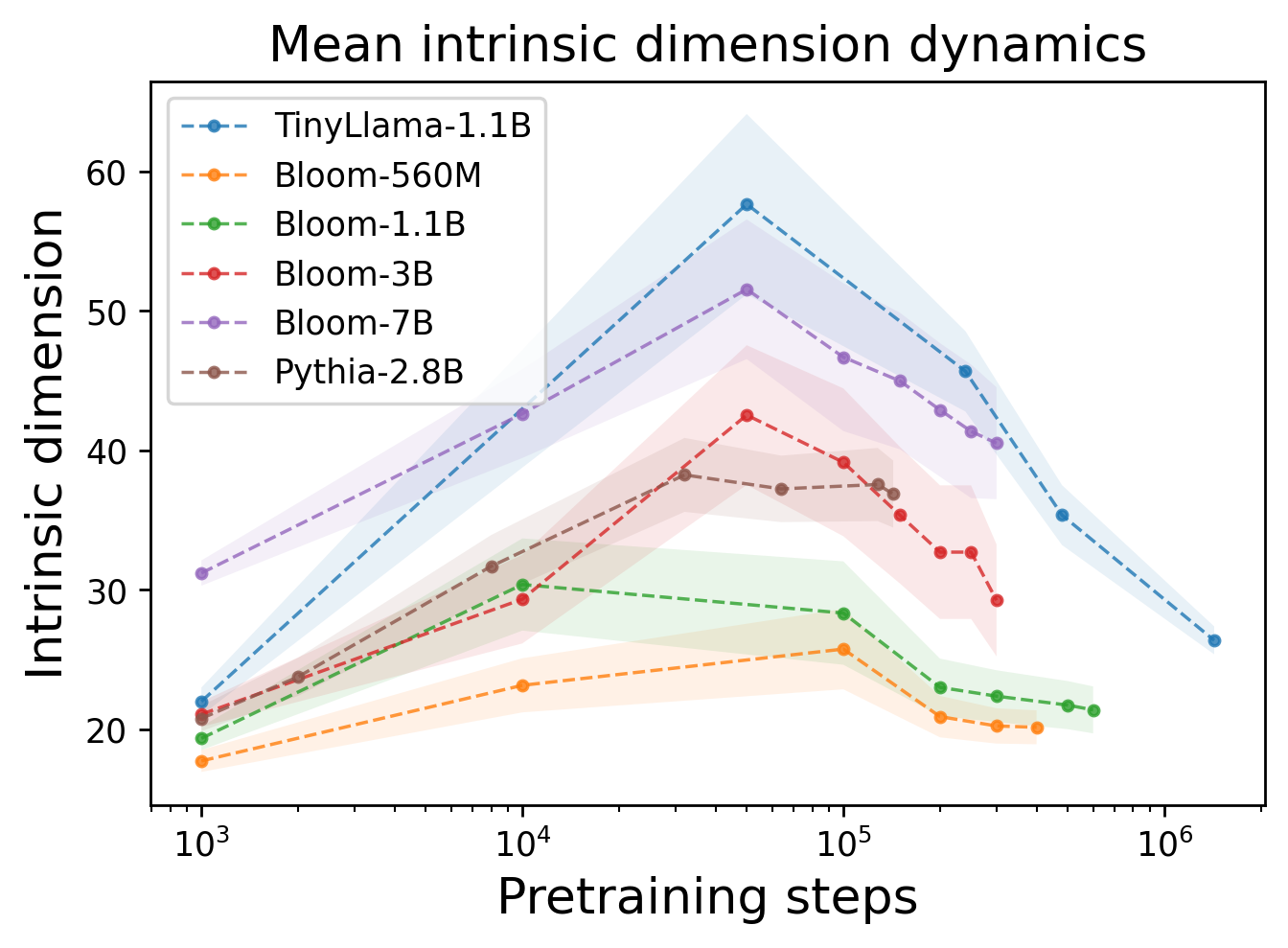
Local internal dimension profile for several language models
These insights deepen our understanding of transformer architectures and open new opportunities to increase the efficiency of training and inference of such models

The results of this work were presented at the EACL-2024 conference. More details can be found in the preprint.