 Никита Драгунов
Никита Драгунов
Обработка текста на уровне предложений оказалась сравнимой с традиционными LLM
Большинство современный больших языковых моделей работают в авторегрессионном потокенном режиме: они формируют следующий токен в последовательности на основе предыдущих. Такой подход облегчает обучение и позволяет моделям создавать связные тексты, однако для длинных последовательностей возникает проблема квадратичного роста вычислительной сложности.
Недавно был предложен подход под названием Large Concept Models (LCM), авторы которого попытались преодолеть эту трудность, перейдя от потокенной обработки текста к обработке эмбеддингов целых предложений. Исследователи экспериментировали с несколькими архитектурными решениями, основными из которых стали авторегрессионный подход на основе MSE-лосса и диффузионный подход. И хотя это существенно уменьшило длину обрабатываемого контекста (вместо десятков и сотен токенов обрабатывается один эмбеддинг), авторегрессионные LCM показали низкую стабильность, в то время как их диффузионный вариант не имел преимуществ в скорости.
Исследователи из команды «Интерпретируемый ИИ» лаборатории FusionBrain AIRI решили сделать следующий шаг в развитии идеи LCM и предложили новую модель под названием SONAR-LLM. Предлагаемая архитектура основана на авторегрессионном трансформер-декодере, который работает с эмбеддингами предложений и использует кросс-энтропийную функцию потерь во время обучения.
В SONAR-LLM текст разбивается на предложения, каждое из которых кодируется в вектор размерности 1024 с помощью замороженного SONAR‑энкодера, разработанного авторами оригинальной идеи. SONAR-LLM генерирует эмбеддинг следующего предложения, который подаётся в замороженный SONAR‑декодер. При этом во время обучения на каждом шаге SONAR‑декодер получает на вход не только эмбеддинг предложения, но и предыдущие токены правильного предложения и предсказывает следующий токен (teacher forcing). Наконец, на предсказанном токене минимизируется кросс-энтропия по параметрам модели.
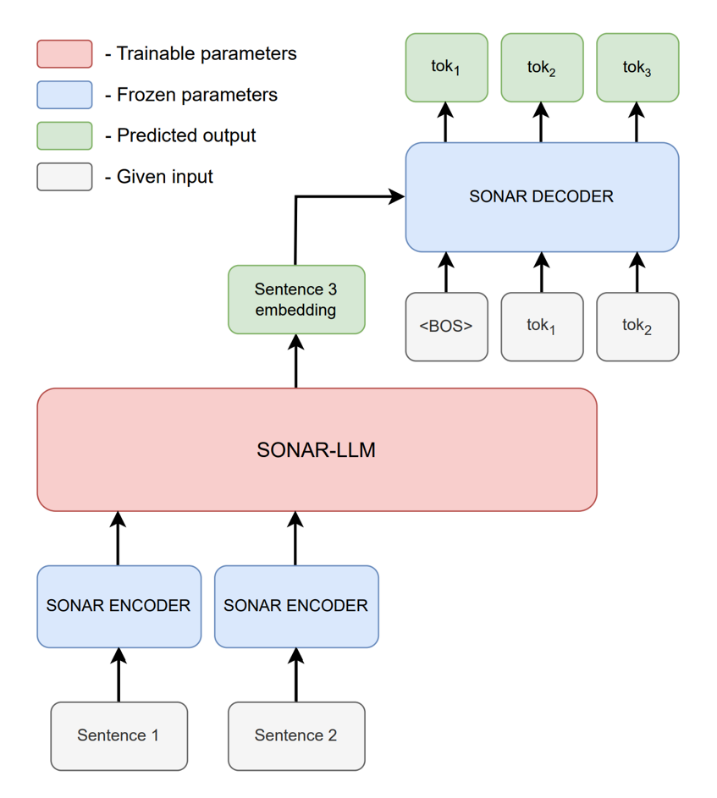
Схема SONAR-LLM
В ходе экспериментов исследователи из AIRI сравнили SONAR-LLM с оригинальными LCM, а также традиционной LLM (архитектура Llama 3) по нескольким критериям: масштабируемость, качество генерации, способность к суммаризации и эффективность на длинных текстах. Новая модель не всегда превосходила LLM на тестах, но уверенно обгоняла оригинальные LCM. Эти исследования показали, что обработка текста на уровне предложений может стать серьёзной альтернативой привычному потокенному подходу.
Больше деталей можно найти в научной статье, весь код доступен на GitHub.






