 Андрей Галичин
Андрей Галичин
В больших языковых моделях нашли ответственные за рассуждения признаки
Изначальной задачей языковых моделей было просто предсказание наиболее вероятного слова (токена) в некоторой последовательности. Применение к ним трансформерной архитектуры вместе с увеличением размеров моделей и обучающих данных привело к революционному росту качества генерируемых текстов, практически не отличимых от человеческих.
Сегодня новый виток разработки больших языковых моделей (LLMs) связан с развитием рассуждающего поведения, в рамках которого нейросеть разбивает задачу на несколько шагов, а также рефлексирует. Популярными моделями, которые продемонстрировали такое поведение, стали o1 от Open AI и DeepSeek-R1.
Несмотря на впечатляющий прогресс в способностях, довольно мало известно о том, как рассуждения закодированы внутри LLM. Чтобы интерпретировать такое поведение, команда исследователей из AIRI обратила внимание на тот факт, что при рассуждениях модели часто используют слова "wait", "maybe", "alternatively", "however" и им подобные, которые явно сигнализируют о неуверенности и переосмыслении.
Ученые воспользовались методом Sparse Autoencoders (SAE), который раскладывает активации модели на разреженные и интерпретируемые признаки, соответствующие определенным человеческим концептам. Они применили технику к представлениям модели DeepSeek‑R1-Llama-8B, выделив около 65 тысяч признаков. Среди них авторы отыскали те, что проявляются в момент генерации слов, связанных с рассуждениями. После ручной проверки им удалось найти признаки неуверенности, исследования, самокоррекции и другого характерного поведения.
Чтобы доказать, что найденные признаки действительно связаны с рассуждениями, исследователи провели серию steering-экспериментов. Оказалось, что, если усиливать соответствующие признаки, модель генерирует на 13-20% более длинные рассуждения и точнее решает задачки из математического бенчмарка. Вместе с этим авторы выяснили, что эти признаки возникают только у специфически дообученных рассуждающих моделей.
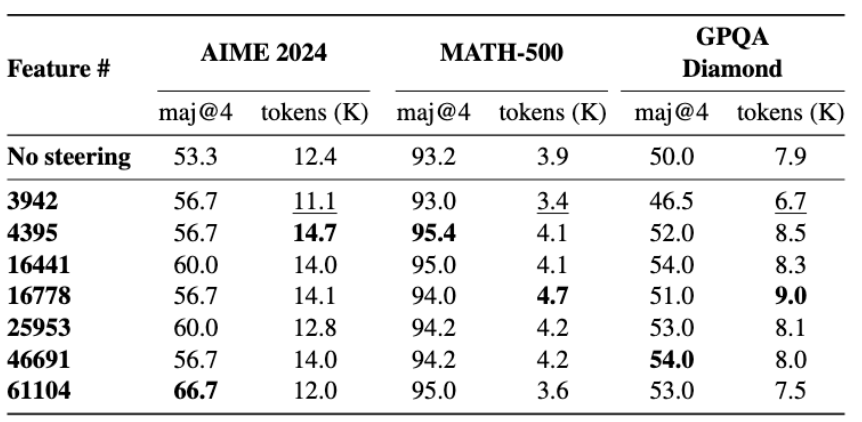
Результаты усиления некоторых признаков на математических бенчмарках. Растёт качество и длина ответов.
Исследователи отмечают, что работа по интерпретируемости ещё далека от завершения. В частности, они достоверно нашли не все признаки, ответственные за рассуждения. Кроме того, есть недостатки и у метода SAE.
Больше деталей можно найти в научной статье, код работы также выложен на GitHub.






