 Айдар Булатов
Марат Хамадеев
Айдар Булатов
Марат Хамадеев
Новый бенчмарк проверит умение больших языковых моделей искать информацию в длинных контекстах
Контекстом в языковых моделях называют длину текста, подаваемого на вход, который они способны обработать и усвоить заложенную там информацию. Увеличение контекста позволяет расширить число сценариев, при которых большую языковую модель (LLM) можно использовать «из коробки», без необходимости дообучать на новом домене данных. Длинные контексты позволяют также совершать сложные пошаговые рассуждения или применять модели в других модальностях.
Сегодня размеры LLM, разрабатываемых лабораториями по всему миру, демонстрируют стремительный рост. Это увеличивает их способности и навыки, но одновременно требует пропорционально увеличивать контекстное окно, а также обеспечить его эффективное использование.
Одним из самых популярных способов проверить такую эффективность стал бенчмарк Needle in a Haystack. Он проверяет способность модели находить небольшие кусочки информации в контекстах длиной до нескольких десятков миллионов токенов. Сегодня Needle in a Haystack стал, де-факто, стандартом для многих разработчиков, из-за чего они часто включают в обучающую выборку схожие задачи, переобучая свои модели и делая метрики бенчмарка необъективными. К сожалению, существует не так много хороших несинтетических бенчмарков, работающих на длинных контекстах, чтобы давать дополнительные оценки работе LLM с контекстом.
Этой проблемой серьёзно озаботились исследователи из AIRI, МФТИ и Лондонского института Математических Наук. Результатом их работы стал BABILong — усложнённая версия бенчмарка Needle in a Haystack, которая проверяет способность моделей выполнять логические задачи в длинных контекстах.
Название нового бенчмарка отражает его заточенность под большие контекстные окна, а также использование задач из датасета bAbI, созданного для тестирования интеллектуальных систем. Всего BABILong состоит из 20 задач, которые проверяют выполнение базовых вычислений, объединение информации из нескольких фактов и логическое мышление. Условия задач и вопросы были спрятаны в художественных текстах из датасета PG19.
Авторы подвергли проверке три десятка актуальных моделей, включая как проприетарные (GPT-4o, Gemini), так и открытые (Llama 3.1, Qwen 2.5). Оказалось, что даже самые лучшие из них демонстрируют существенное падение качества с увеличением длины контекста. Еще меньших успехов добиваются методы расширения контекста с помощью Retrieval-Augmented Generation (RAG).
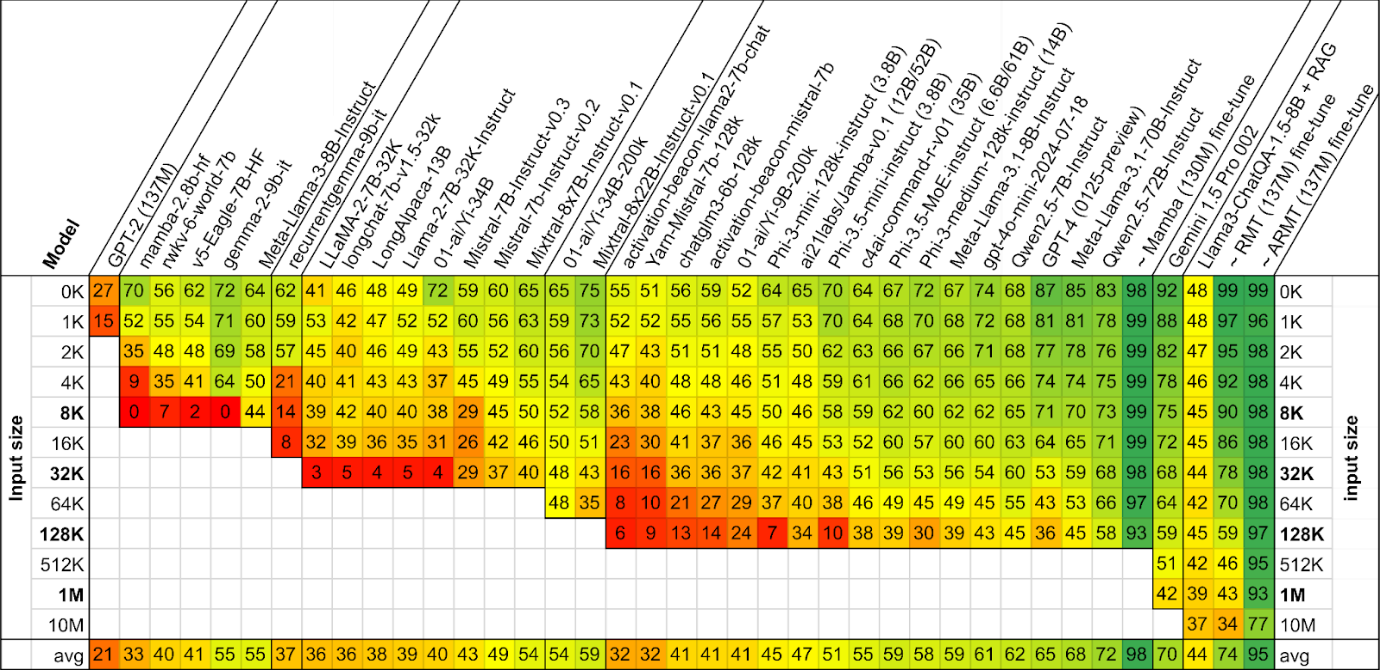
Результаты тестирования моделей, отсортированных по длине контекста. Цветом и цифрами обозначена доля верно решенных задач данной длины в процентах. Знаком «~» обозначены специально обученные модели.
Исследователи также проверили, как проходят BABILong модели, дополненные рекуррентностью на уровне сегментов. Про этот новый метод увеличения контекста под названием Recurrent Memory Transformer (RMT), придуманный той же командой, мы уже рассказывали ранее. Учёные экспериментировали с архитектурами и выяснили, что модель GPT-2, аугментированная продвинутой версией RMT (ARMT) поддерживает качество 80% вплоть до длины контекста 50 миллионов токенов.
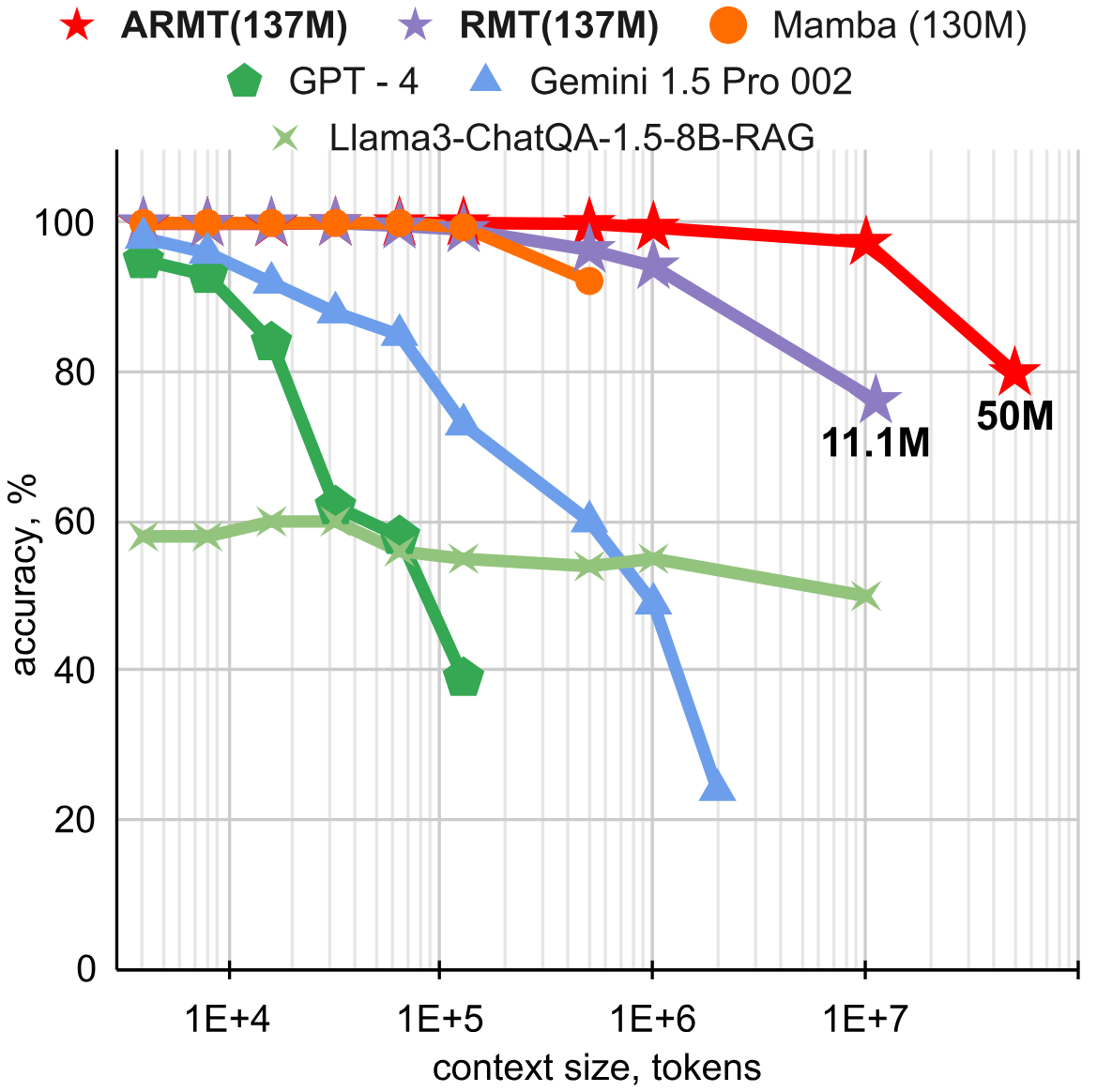
Сравнение RMT и ARMT на задаче QA1 бенчмарка BABILong
Исследование опубликовано в сборнике трудов конференции NeurIPS 2024.






