Виталий Протасов
Виталий Протасов
Африкаанс и словенский оказались лучшими донорами для обучения на многоресурсных языках с целью переноса знания на малоресурсные
В последние годы компьютерная лингвистика переживает небывалый подъём благодаря изобретению трансформерный нейросетей, которые легли в основу больших языковых моделей (large language models, LLMs). Количество параметров открытых и проприетарных LLMs из года в год демонстрирует экспоненциальный рост. Подобным же образом растёт и объём текстовых датасетов, на которых обучают языковые модели. Чем более полным и разнообразным будет обучающий набор данных, тем выше будет качество LLM и шире языковое покрытие.
При этом разные языки вносят в датасеты различный вклад. Так, английский язык традиционно представлен корпусом текстов, на порядок превышающий таковой у остальных, даже хорошо распространенных языков. Для исчезающих же языков, на которых написано слишком мало текстов и говорит слишком мало людей (их ещё называют малоресурсными языками), невозможно обучить качественную LLM, из-за чего они не поддерживаются современными технологическими сервисами на основе искусственного интеллекта: электронными переводчиками, ИИ-ассистентами и тому подобным.
Наиболее естественным способом решить эту проблему стало трансферное обучение или обучение с переносом знаний (transfer learning), в котором модель предобучают на большом датасете, а дообучают на малоресурсном домене. На сегодняшний день существует несколько мультиязычных моделей, работающих по такому принципу, например, mBERT, XLM-R или mT5, а также кросс-языковых бенчмарков (XGLUE и XTREME), покрывающих в сумме около ста языков. Это существенно меньше, чем число всех языков в мире, которое на начало этого года составило 7151, более трети из которых находится на грани исчезновения.
Другой аспект проблемы связан с тем, что в большинстве работ в качестве основного языка-донора выступает английский язык — это естественно, учитывая его лидерство в представленности. Однако нет оснований считать, что это самый подходящий язык с точки зрения переноса знаний. Эти факты побудили исследователей из AIRI при участии коллег из Сколтеха не только расширить диапазон языков, в особенности редких, с которыми проводятся эксперименты, но и выяснить, для каких языков трансферное обучение происходит наиболее эффективно.
Для этого авторы собрали корпусы данных для 189 языков, которые они поделили по объему текстов на 158 многоресурсных и 31 малоресурсный. Таким образом, исследованию эффективности переноса знаний подверглись 4898 пар языков. В качестве базовой модели исследователи остановили свой выбор на mT5. Следуя за авторами этой модели, команда обучала её в режиме маскированного языкового моделирования (Masked Language Modeling).
На первом этапе учёные исследовали то, как обучение с переносом знаний из высокоресурсных языков улучшает понимание моделью малоресурсных языков, выбрав в качестве метрики перплексию — чем она меньше, тем лучше. Далее обученные модели решали более конкретные задачи: предсказание части речи слова (POS-tagging), а также машинный перевод, для которого часть текстов была аннотирована.
Результаты экспериментов показали, что эффективность трансферного обучения сильно зависит от языков в паре. Так, перплексия уменьшилась у 16 из 31 малоресурсного языка, при этом африкаанс, словенский, литовский и французский оказались лидерами по числу языков-реципиентов, чью перплексию им удалось уменьшить — 14, 14, 12 и 11, соответственно. Исследователи назвали их «супердонорами». «Суперреципиентами» же стали гуарани и коптский. Похожая картина сложилась при сравнении на конкретных задачах.
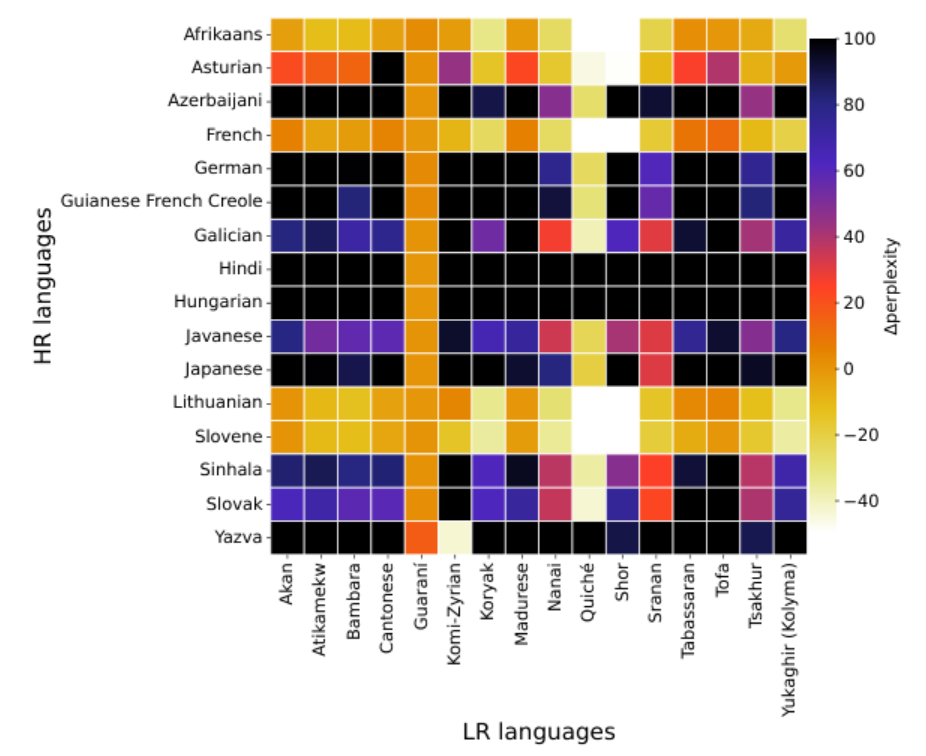
Тепловая карта разницы в перплексии после обучения на высокоресурсных (HR) языках и до
Пытаясь найти факторы, которые влияют на успешность переноса знаний из одного языка в другой, авторы обнаружили несколько закономерностей. Так, на это не влияет положение языка в рейтинге распространённости. Более того перенос происходит хуже, если языки принадлежат к одной семье, но его качество резко вырастает, если они обладают некоторыми общими морфологическими особенностями. Наконец, более высокая степень перекрытия субтокенов в языках, как правило, обеспечивает лучший результат.
Наши эксперименты были проведены только для модели mT5, и для других моделей результаты могут отличаться. Но если будущие исследования найдут аналогичные закономерности и там, то можно будет с осторожностью делать какие-то универсальные выводы о качестве переноса в различных парах языков.

С деталями работы можно ознакомиться в статье, опубликованной в сборнике трудов воркшопа LoResMT 2024, который проходил в рамках конференции ACL 2024.