 Марат Хамадеев
Марат Хамадеев
Устойчивые гомологии помогли надёжно определить машинное происхождение текстов
С каждым годом появляются всё новые нейросетевые языковые модели, а сгенерированные ими тексты становится всё сложнее отличить от написанных человеком. Уже сейчас это помогает сильно упрощать множество сфер человеческой деятельности. В то же время, развитие этих технологий снижает ценность и доступность авторских — то есть, написанных человеком — текстов. Эта проблема особенно актуальна для образования и творческих профессий.
Перед экспертами в области машинного обучения естественным образом встает задача обнаружения искусственно сгенерированных текстов (artificial text detection, ATD). Такие методы стали активно появляться в последние годы, но они не универсальны — в большинстве своём, ориентированы на противодействие конкретным генерирующим моделям; также они имеют и иные ограничения. Некоторые исследователи призывают разработчиков внедрять статистические искажения в выдачу модели, создав таким образом аналог водяных знаков для текстов; кто-то предлагает централизованно хэшировать каждый генерируемый текст, чтобы потом облегчить его обнаружение. Наконец, есть и те, кто высказывает мнение, что создать идеальный детектор ИИ-текстов невозможно.
Команда исследователей из нескольких российских институтов не готова сдаваться так быстро. Учёные обнаружили, что определённые численные представления достаточно длинных текстовых отрывков имеют весьма примечательную геометрию. В частности, как выяснилось, одна из её статистик — так называемая внутренняя размерность — может служить достаточно надёжным индикатором того, «естественный» ли это текст (то есть, написанный человеком) или же он «искусственный» (сгенерированный при помощи нейросетевой модели). На основе этого наблюдения команда смогла создать надёжный и универсальный детектор «искусственных» текстов.
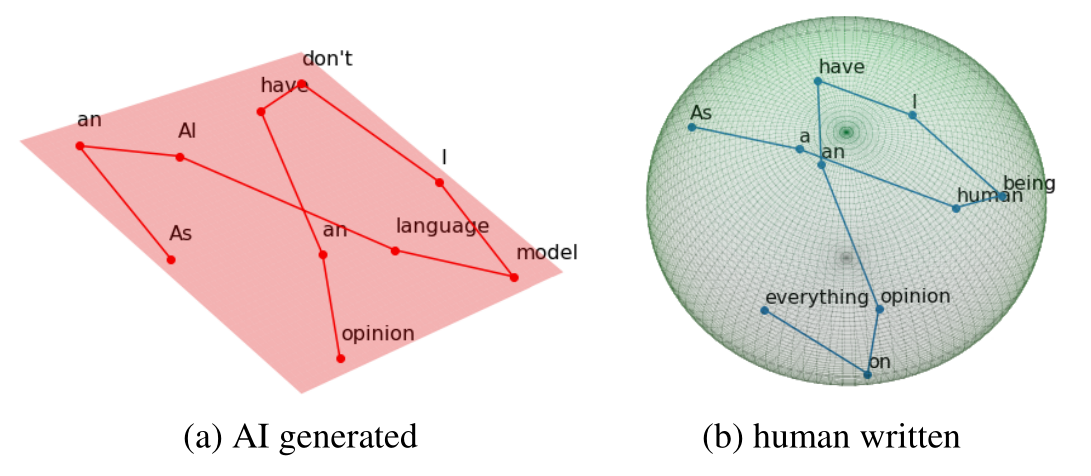
Схематическое представление основной идеи: представление сгенерированного текста (слева) имеет меньшую внутреннюю размерность, чем представление текста, написанного человеком (справа)
Другие исследователи, работающие в данной области, уже предлагали обращаться к размерностям многообразий, построенных на базе разных представлений данных либо весов нейросетевых моделей. Но даже если предположить, что набор данных лежит на некоторой поверхности в многомерном пространстве, оценить её размерность нелегко из-за различного рода шума в данных и неравномерного распределения набора точек.
Авторы нового подхода предложили вместо этого оценивать геометрию каждого текста как отдельного объекта, естественно, если он достаточно длинный (порядка 200 слов или более) и достаточно осмысленный. Произведённые современными языковыми моделями тексты содержат очень мало грамматических, синтаксических или локальных семантических несоответствий и, как правило, вполне соответствуют этим условиям.
В соответствие с предложенным методом, первым делом текст пропускается через предварительно обученную трансформерную модель, и на выходе получается набор контекстно-зависимых эмбеддингов – по одному для каждого токена текста (знака препинания, слова или его части, если оно целиком не входит в ограниченный словарь модели). С точки зрения математики такой эмбеддинг — это вектор фиксированной длины (или же просто точка в евклидовом пространстве), численное значение которого обусловлено как самим токеном, так и его контекстом.
Следующий шаг — оценить размерность многомерной поверхности, на которой лежит этот набор точек — представляет изрядную сложность. Дело в том, что геометрические представления реальных данных очень часто демонстрируют иерархическую структуру, и их размерность зависит от масштаба, на котором они исследуются. Поэтому, в качестве приблизительной оценки, часто используются те же приёмы, что и для оценки сложности фракталов.
Существуют множество способов оценить внутреннюю размерность, и их различия обусловлены разными предположениями о структуре данных. Авторы статьи сравнили результаты их применения к контекстно-зависимым эмбеддингам текстов и затем предложили новый метод, основанный на концепте персистентных гомологий (persistent homology) из топологического анализа данных. Как показали эксперименты, предложенный ими метод — Persistence Homology Dimension — оказался более устойчивым к смене стиля или длины текста, а также различным видам лингвистического шума.
Исследователи работали с двумя корпусами текстов: «естественных» и «искусственных», то есть сгенерированных различными языковыми моделями. Первый был собран из текстов разных стилей и из разных источников, включая статьи из Википедии, посты на Reddit’е и вопрос-ответы в разных областях знания с сайта StackExchange. «Искусственные» тексты были созданы по-разному, в зависимости от конкретной задачи, но большинство — это либо развёрнутые ответы на вопросы, либо сгенерированные продолжения коротких отрывков (в два предложения). Использовались разные модели текстовой генерации: GPT2-XL, OPT13b, GPT3.5.
Главное, что показали эксперименты — уверенное различие внутренней размерности для текстов, написанных человеком и машиной. Наибольшей размерностью обладали итальянские и испанские человеческие тексты (10 ± 1), наименьшей — японские и китайские (7 ± 1). Однако, независимо от языка, машинный текст демонстрировал, в среднем, на полторы единицы меньшую размерность с хорошей статистической значимостью.
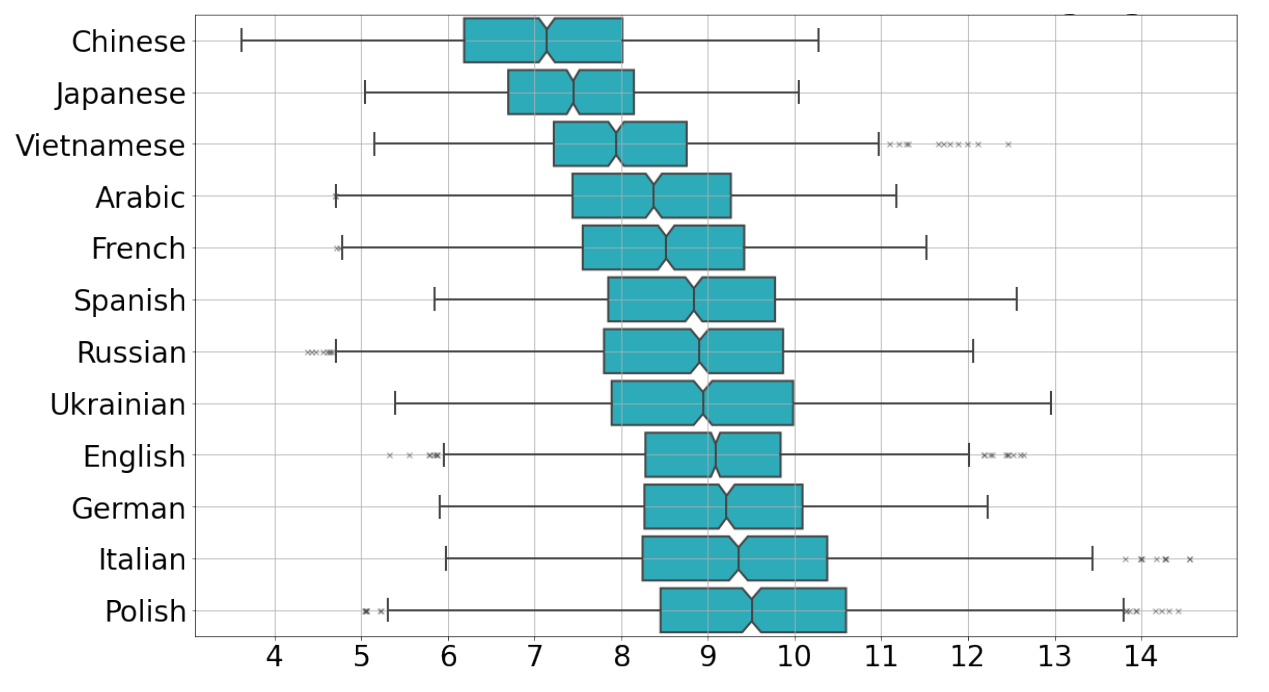
Внутренняя размерность «натуральных» текстов на разных языках
В ходе экспериментальной проверки метод, предложенный исследователями, превзошёл другие ATD-методы, в том числе, GPTZero и OpenAI detector, предоставленный создателями ChatGPT. Новый подход продемонстрировал ещё одно важное преимущество: меньшую предвзятость к текстам от не носителей языка.
Код и данные выложены на GitHub, а подробности исследования можно узнать из статьи, опубликованной в сборнике трудов конференции NeurIPS 2023.






