Алла Чепурова
Алла Чепурова
Большие языковые модели оказались способны наполнять графы знаний
Большинство знаний человечества в нашем веке хранится в виде текста. Это самый естественный способ выражения информации для человека после речи. Однако он не очень хорошо структурирован, из-за чего это не самый оптимальный способ организации базы знаний.
Вместо этого предпочтительнее использовать графы знаний (Knowledge Graphs, KGs) — структуры данных, в который сущности и их отношения представлены в виде узлов и рёбер. В таком виде граф знаний можно построить как совокупность триплетов вида «субъект, отношение, объект». Высокая степень организации информации в графах делает их подходящими для поисковых, вопросно-ответных, рекомендательных и прочих систем. Кроме того, связывание с графами знаний больших языковых моделей (large language models, LLMs) способно уменьшить галлюцинации в последних.
Недостатком графов по сей день остаётся трудоёмкость их наполнения, которая проводится экспертами вручную. Поэтому создание методов автоматизации этой работы является весьма актуальным.
Так как извлечение знаний происходит чаще всего из текстов, естественным было попытаться сделать это с помощью LLM. Недавнее исследование показало, что при этом можно обойти проблему сбора обучающих данных, если применить внутриконтекстное обучение и следование инструкциям. Тем не менее, в литературе такая задача была признана асимметричной, сама идея о построении графой знаний с помощью LLM бесперспективной.
Учёные из МФТИ, AIRI и Лондонского института Математических Наук доказали, что это не так. Они создали алгоритм под названием Prompt Me One More Time, который справляется с наполнением графа знаний с помощью описанного выше подхода.
Новый метод состоит из трёх этапов. На первом языковая модель извлекает из текста триплеты-кандидаты. Имена сущностей и отношений в них могут не соответствовать форматам, принятым в выбранном KG, поэтому на втором этапе алгоритм приводит их в нужное соответствие (нормализует). Наконец, в самом конце происходит отсеивание нормализованных кандидатов на соответствие онтологии KG, то есть ограничениям на то, какие сущности какими отношениями могут быть связаны.
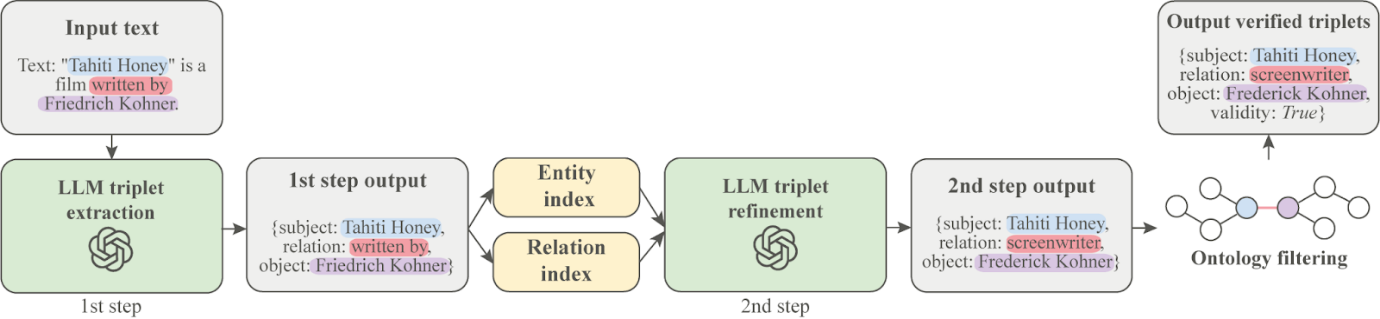
Схема метода Prompt Me One More Time
Для проверки нового подхода авторы выбрали для наполнения крупнейший open-source граф знаний WikiData, а для всех шагов, кроме последнего, они использовали модель OpenAI gpt-3.5-turbo. Чтобы провести корректную оценку эффективности, исследователи выбрали синтетический датасет SynthIE и сравнивали свой алгоритм со специализированной моделью SynthIE T5-large.
В ходе работы выяснилось, что в SynthIE триплеты в разметке часто не соответствовали текстам. Чтобы исправить этот недостаток, учёные вручную добавили тексты из Википедии про сущности из таких триплетов. Сравнение на скорректированном датасете вместе с ручной оценкой трёх аннотаторов показало, что Prompt Me One More Time лучше справляется с задачей, чем SynthIE T5-large.
При этом наборы триплетов, которые корректно восстанавливали оба подхода, заметно отличались. Исследователи пришли к выводу, что разработка комбинированных подходов может в целом увеличить производительность метода.
Больше подробностей можно найти в статье, представлена на воркшопе TextGraphs-17 конференции ACL-2024.