 Марат Хамадеев
Марат Хамадеев
Разреженное пространство параметров помогло сделать трансформеры компактнее
Размеры моделей в машинном обучении, в особенности трансформеров, в последние годы уверенно растут. Параллельно с этим увеличиваются затраты на их обучение и потребности в больших датасетах, которые могут позволить себе не все исследовательские группы. Наконец, объёмы памяти, требуемые для развёртывания таких моделей, становятся настолько большими, что их уже невозможно запускать на отдельных видеокартах, что сокращает сценарии их практического использования.
Вместо обучения с нуля распространённой практикой стало дообучение на интересующем домене (файнтюн) уже готовых моделей, которые содержат в себе большое количество самых разнообразных знаний. Такие модели называют фундаментальными (foundation models), а их веса часто находятся в открытом доступе и доступны для скачивания всем желающим.
Файнтюн существенно сокращает время по сравнению с обучением с нуля, однако выигрыша в используемой GPU-памяти здесь нет, так как для каждого тренируемого слоя в модели граф вычислений (NN computational graph) все еще должен хранить и матрицу весов, и матрицу градиентов. Выигрыш по памяти дают параметрически-эффективные методы дообучения (parameter-efficient fine-tuning, PEFT). В них градиенты хранятся только для части весов.
Существует несколько подходов к PEFT. Например, завоевавший популярность в ML-сообществе метод LoRA представляет матрицу поправок в виде произведения двух низкоранговых матриц, кратно сокращая сложность оптимизации. Однако в случае с трансформерами этот и многие другие методы обычно применяют к модулю внимания, игнорируя блоки с многослойными перцептронами (multilayer perceptron, MLP).
На этот факт обратила внимание команда исследователей из AIRI и Сколтеха. Учёные отталкивались от предположения о том, что существует базис, в котором матрица градиентов имеет сильно разреженный вид, что можно использовать для сокращения числа параметров при обучении.
Они ввели новый класс слоя в PyTorch под названием SparseGradLinear, который обеспечивает переход в такое разреженное пространство, расчёт в нем градиентов и возврат обратно. При этом исследователи вычисляли матрицы переходов, факторизируя тензор, собранный из градиентов MLP-слоев. Оказалось, что они одинаковы во всей модели для слоёв заданного типа, а значит их достаточно найти один раз перед процедурой файнтюна. Новый метод получил название SparseGrad.
Авторы экспериментировали с тремя открытыми моделями: BERT и RoBERTa в базовой и большой версии и декодерной архитектурой LLaMa-2. Для оценки первых двух использовался бенчмарк GLUE, для последней — корпус OpenAssistant Conversations и вопросы из Inflection-Benchmarks. Оказалось, что без существенной деградации модели SparseGrad позволяет сократить число обучаемых параметров до 1% от исходного. Эксперименты показали, что при прочих равных условиях новый подход превосходит по метрикам современные популярные методы: репараметризационный LoRA и селективный MeProp.
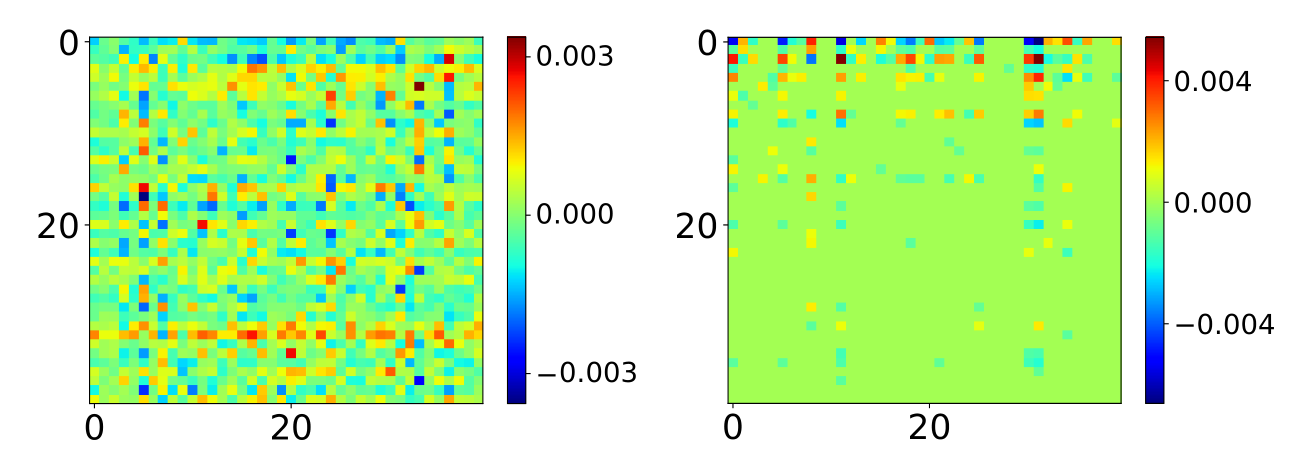
Матрица градиентов пятого MLP-блока BERT до (слева) и после (справа) преобразования SparseGradLinear
Статья с результатами работы была представлена авторами на конференции по обработке естественных языков EMNLP 2024.






