Марат Хамадеев
Марат Хамадеев
Трансферное обучение помогло сделать ансамблирование нейронных сетей эффективнее
Хорошее обучение нейросетей специфичным задачам невозможно без качественного и богатого датасета. К сожалению, на практике сборка таких данных обходится слишком дорого либо вообще невозможна. Чтобы справится с этой трудностью, специалисты применяют различные техники, например, доменную адаптацию модели с помощью трансферного обучения или, по-другому, обучения с переносом знаний (transfer learning).
Суть этого подхода заключается в предобучении модели на большом, но общем датасете с последующей её подстройкой с помощью малого, но целевого домена. Эта техника работает благодаря тому, что при предобучении происходит знакомство с общими свойствами, которые присущи всем объектам, включая целевые. Например, прежде чем натренировать нейросеть рисовать портреты в стиле известных художников, ей можно показать фотографии и рисунки множества людей, поскольку во всех случаях лица будут обладать схожими признаками. Совсем недавно мы рассказывали, как учёные из AIRI их коллеги смогли оптимизировать этот процесс для генеративно-состязательных сетей, сократив число параметров в пять тысяч раз.
Параллельно специалисты стремятся повысить точность моделей, собирая их в ансамбли. Для этого берётся несколько нейронных сетей, каждая из которых инициализируется случайным образом, после чего они обучаются на одну задачу. Усреднение по предсказаниям такого ансамбля показывает более высокое качество, чем предсказание одной нейронной сети.
Коллектив учёных под руководством Дмитрия Ветрова ищет способы эффективно объединить обучения с переносом знаний и ансамблевое обучение. Как правило, при таком комбинировании выделяют две противоположные стратегии: локальное и глобальное глубокое ансамблирование (deep ensembling, DE).
Локальные ансамбли предобучаются всего один раз, после чего из этой контрольной точки происходит тонкая настройка каждой сети из ансамбля. В результате модели будут похожи друг на друга, или, говоря техническим языком, будут находиться в одном регионе пространства весов или бассейне предварительного обучения — по этой причине стратегия называется локальной. В глобальных ансамблях каждая нейронная сеть предобучается независимо. Это даёт большее разнообразие и, как следствие, повышает качество предсказания. Однако глобальное DE существенно дороже обучать по сравнению с локальным DE.
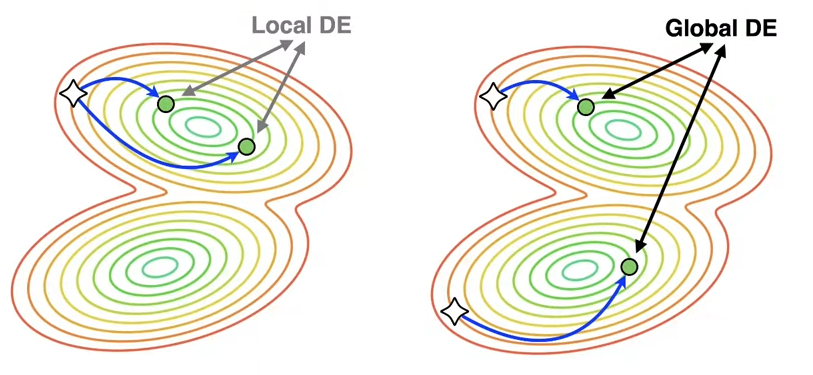
Различие между локальным и глобальным глубокими ансамблями в пространстве весов сетей. Звёздочками обозначены предобученные контрольные точки, зелёным точками — точно настроенные модели, синей стрелкой — траектория оптимизации.
Пытаясь совместить преимущества обеих стратегий, исследователи обратились к методу Snapshot Ensemble (SSE), используемому в глубоких ансамблях, суть которого заключается в циклической настройке темпа обучения. В такой технике на пиках темпа нейросеть может покинуть локальный бассейн, после чего в ближайшем минимуме можно зафиксировать контрольную точку. Как показывает практика, её эффективность зависит от гиперпараметров: амплитуды и периода циклов.
В ходе экспериментов учёные подтвердили, что эффективность применения SSE к обучению с переносом знаний зависит от гиперпараметров, достигая максимума при определенном оптимуме. Однако этот максимум не даёт никаких преимуществ перед традиционным локальным DE. Тогда авторы обратили внимание на то, что обычный SSE производит последовательность тонких настроек, из-за чего модели деградируют при большом размахе темпа обучения, который потенциально способен дать большее разнообразие.
Вместо этого они предложили производить параллельную настройку, каждый раз начиная с первой сети. Из-за того, что в пространстве весов такая схема имеет звездообразную форму, метод получил название StarSSE. Эксперименты показали, что новый подход при определенных гиперпараметрах повышает по производительности локальное DE.
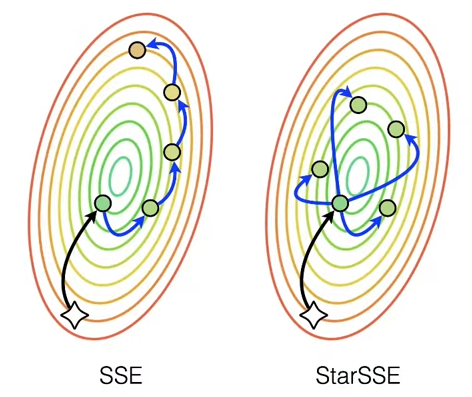
Различие между SSE и StarSSE
Помимо этого авторы предложили способ, как ускорить инференс, то есть итоговую работоспособность обученной модели. Для этого они использовали так называемые «супы» из моделей — технику ансамблирования, при которой усредняются не предсказания, а сами веса. Расчёты, проделанные исследователями, показали, что StarSSE-супы работают эффективнее, чем SSE-супы и даже локальные DE-супы.
Код авторов открыт для скачивания на GitHub, с деталями исследования можно ознакомится в статье, опубликованной в сборнике трудов конференции NeurIPS 2023.