 Vitaly Protasov
Vitaly Protasov
Afrikaans and Slovene were found to be the best donors for cross-lingual transfer between high-resource and low-resource languages
In recent years, computational linguistics has experienced an unprecedented rise due to the invention of transformer neural networks, which serve as the foundation for large language models (LLMs). The number of parameters in both open and proprietary LLMs has shown exponential growth year after year. Similarly, the volume of text datasets used to train language models is also increasing. The more comprehensive and diverse the training dataset, the higher the quality of the LLM and the broader its language coverage.
Different languages contribute variously to these datasets. For instance, English is traditionally represented by a corpus of texts far exceeding that of other, even well-represented languages. In contrast, for endangered languages — those with too few texts and speakers (often referred to as low-resource languages) — it is impossible to train a quality LLM, resulting in their lack of support from modern AI-based technological services such as machine translators, AI assistants, and similar tools.
The most natural way to address this issue has been through transfer learning, where a model is pre-trained on a large dataset and then fine-tuned on a low-resource domain. Several multilingual transformer models operate on this principle, such as mBERT, XLM-R, or mT5, and cross-lingual benchmarks (XGLUE and XTREME) that cover around one hundred languages. This is significantly fewer than the total number of languages in the world, which stood at 7,151 at the beginning of this year, with more than a third at risk of extinction.
Another aspect of the problem is that English is the primary donor language in most studies. This is understandable given its prominence. However, there is no reason to believe that it is the most suitable language for knowledge transfer. These facts prompted researchers from AIRI, in collaboration with colleagues from Skoltech, not only to expand the range of languages being experimented with, particularly rare ones but also to investigate which languages benefit most effectively from transfer learning.
To achieve this, the authors collected a dataset for 189 languages, dividing them into 158 high-resource and 31 low-resource languages based on text volume. Thus, the effectiveness of knowledge transfer was examined across 4,898 language pairs. For the base model, the researchers chose mT5. Following the authors of this model, the team trained it using Masked Language Modeling (MLM).
At the first stage, the researchers investigated how transfer learning from high-resource languages improves the model's understanding of low-resource languages, using perplexity as a metric — lower values indicate better performance. The trained models then performed more specific downstream tasks: predicting the part of speech of a word (POS-tagging) and machine translation, for which some texts were annotated.
The results of the experiments showed that the effectiveness of transfer learning heavily depends on the languages in the pair. Specifically, perplexity decreased for 16 out of 31 low-resource languages, with Afrikaans, Slovene, Lithuanian, and French emerging as leaders in terms of the number of recipient languages for which they managed to reduce perplexity — 14, 14, 12, and 11, respectively. The researchers referred to them as "super-donors". The "super-recipients" were Guarani and Coptic. A similar pattern was observed when comparing downstream tasks.
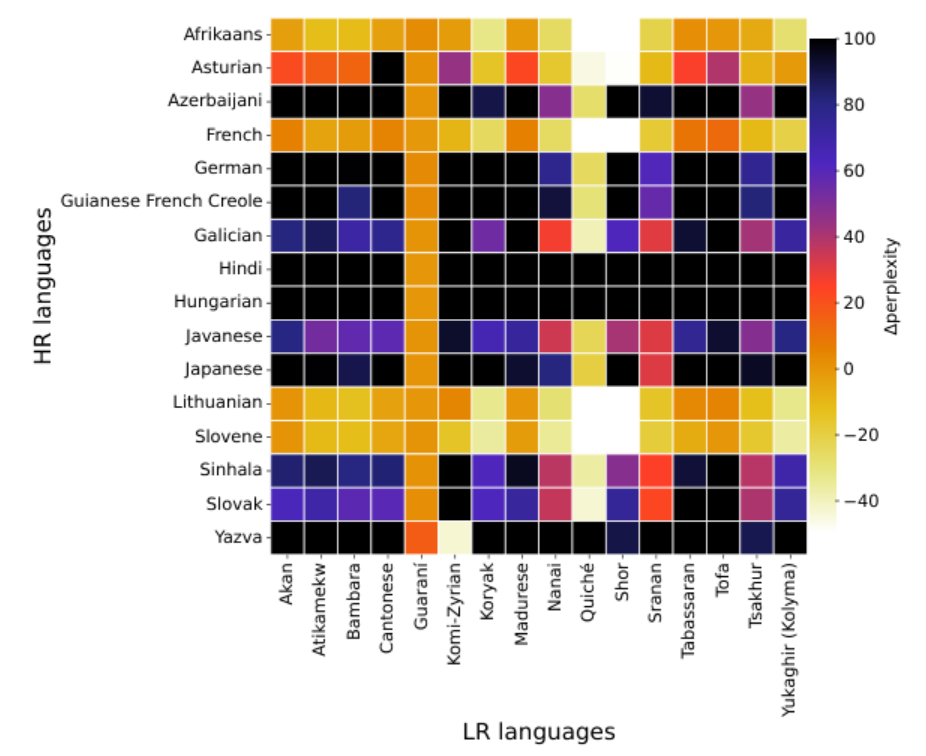
The heatmap represents the difference in perplexity after cross-lingual transfer by the continued pretraining on donors versus the zero-shot setup
In trying to identify factors that influence the success of knowledge transfer from one language to another, the authors discovered several patterns. For instance, most word order features have no significant impact on this process. HR-LR language pairs from the same families correlate negatively with the results; however, this correlation shifts to positive when they share the same morphological feature as affix. Finally, a higher degree of overlap between subtokens in languages tends to yield better performance in cross-lingual transfer.
Our experiments were conducted only for the mT5 model, and results may vary for other models. However, if future research finds similar patterns there, it may allow us to cautiously draw some universal conclusions about the quality of transfer across different language pairs.

Details of the work can be found in the article published in the proceedings of the LoResMT 2024 workshop, which took place during the ACL 2024 conference.






