 Alexander Tyurin
Alexander Tyurin
New algorithms will accelerate distributed machine learning
The scale of contemporary computational tasks in science and engineering has often surpassed the capabilities of even the most powerful standalone computers in recent years. Distributed computing has emerged as a solution to this problem, where computers work together, united within a specific architecture.
This principle is fully applicable to machine learning. Advanced models require the collaboration of multiple data centers for training and inference, which may differ in hardware, configurations, software, and other conditions and may be located at significant distances from each other for energy consumption reasons. As a result, some clients may execute computations faster, while others experience delays or even fail to participate in the training altogether, leaving room for optimization.
Mathematical optimization methods began to develop around the same time as the advent of the first computing technology. Their application to a particular field must consider the specific form of the objective function. In the case of distributed machine learning, this involves the computation of a loss function, which falls under the category of finite-sum nonconvex optimization.
In synchronous methods based on Stochastic Gradient Descent (SGD), such as Minibatch SGD, computations proceed at the speed of the slowest node, which reduces the overall efficiency of the algorithm. Therefore, it is relevant to create algorithms that allow nodes to operate asynchronously, meaning independently of each other without the need for synchronization at each step, and heterogeneously, with varying execution times.
A team of scientists from AIRI and the King Abdullah University of Science and Technology (KAUST) focused their efforts on this challenge. They not only developed several new algorithms but also investigated their theoretical optimality and efficiency. The researchers also proved new lower bounds on time complexity for decentralized asynchronous optimization.
The Fragile SGD method does not require synchronization and automatically ignores nodes that are too slow or too far from the central node. It uses spanning trees to organize communications between nodes, minimizing data transfer time. Fragile SGD achieves nearly optimal time complexity that is close to the proven lower bounds.
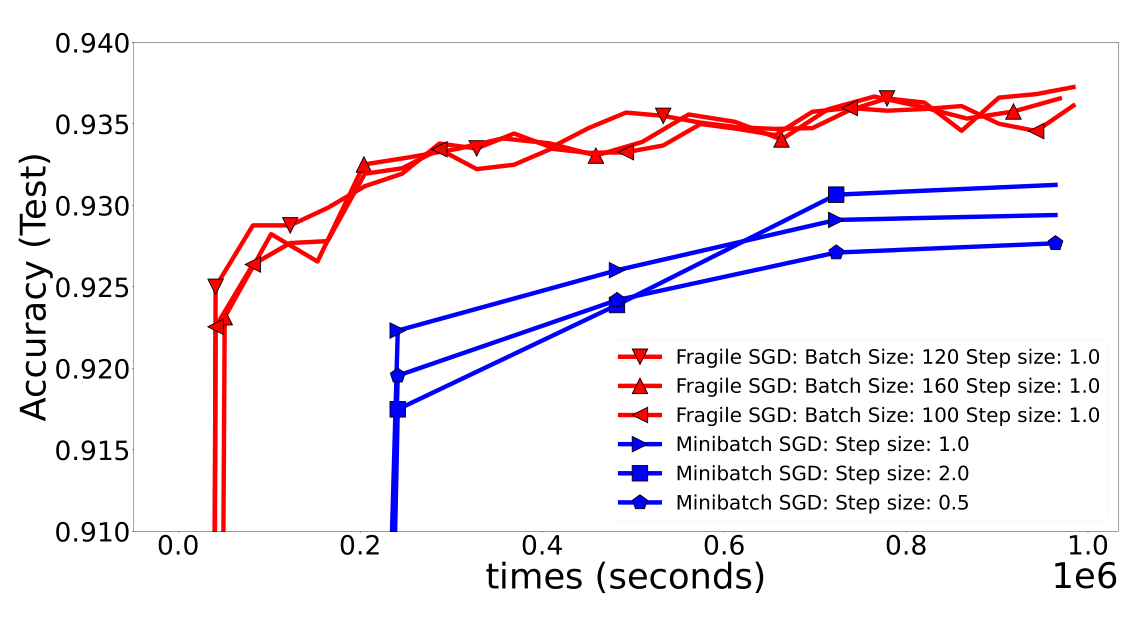
Comparison of the accuracy of Fragile SGD and Minibatch SGD on a 2D-Mesh under slow communication
Amelie SGD is tailored for heterogeneous conditions, where each node may have its own dataset, which is typical for federated learning. The method is proven to be optimal.
One of the key ideas behind the Shadowheart SGD method is a new mathematical framework based on equilibrium time. This defines the optimal time each node should spend on computations and communications, determined by system parameters. Another feature of Shadowheart SGD is the unbiased data compression, which reduces the volume of transmitted data without significantly increasing error.
Finally, the Freya PAGE method is well-suited for tasks with empirical risk and relies on entirely new strategies for collecting stochastic gradients: ComputeGradient and ComputeBatchDifference. The authors demonstrated that Freya PAGE has optimal time complexity in scenarios where the amount of data significantly exceeds the number of devices.
All described methods can adapt to changing computational conditions, which is particularly useful in real systems where device performance can vary over time. The authors presented these findings at the NeurIPS 2024 conference in three scientific papers (1, 2, 3).






