Marat Khamadeev
Marat Khamadeev
Hybrid Uncertainty Quantification improved classification accuracy for ambiguous texts
Many natural language processing tasks are subjective and inherently ambiguous. One such task is determining the toxicity of texts exchanged between internet users. The problem lies in the fact that toxicity can be defined in different ways, which may contradict each other and vary depending on the demographic group to which the sender or receiver of the text belongs. In some cases, the proportion of ambiguous texts can reach 90 percent, making machine classification methods ineffective.
To improve the accuracy of a neural network that filters texts, one can try to predict their ambiguity during the prediction process itself. In this case, classification can be abandoned for some examples, sending them for human review. This approach is called selective classification.
Specialists distinguish two sources of errors: examples outside the distribution of training data and ambiguous examples. In the first case, methods for evaluating epistemic uncertainty arising due to a lack of data work well; in the second case, one uses methods for evaluating aleatoric uncertainty, which arises due to noise and ambiguity in the data. A good state-of-the-art approach should be able to skillfully combine both types of evaluation. The development of such an approach was the goal of a group of researchers fr om several Russian Institutes led by Alexander Panchenko and Artem Shelmanov.
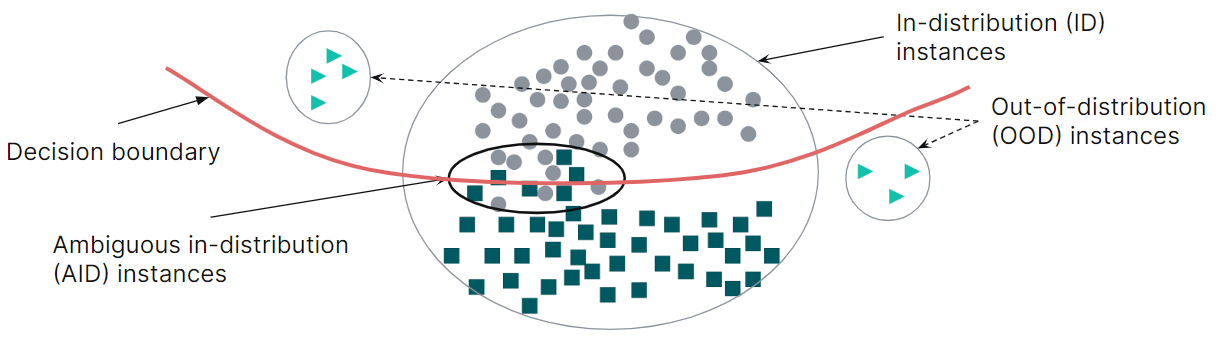
Two types of errors occur in classification problems
Scientists proposed a hybrid uncertainty quantification method for the task of selective classification of texts with ambiguous examples based on ranking. Instead of adding up the absolute values of uncertainties or threshold selection between dominant types of errors as their predecessors used, they suggested to transform the set of examples into a sorted list in ascending order of their uncertainties. Such a transformation does not affect the operation of familiar methods, since the rank monotonically depends on uncertainty, but allows for more correct mixing of them.
The novelty of the work can also be attributed to the approach to mixing, which was named the Hybrid Uncertainty Quantification (HUQ) method. Now the algorithm distinguishes three different cases. If the example is within the training data distribution, the aleatoric uncertainty method with ranking is used only according to it. If this uncertainty is high enough, the estimate is ranked across the entire dataset. Finally, for the remaining part of the examples whose positions are unknown, the algorithm uses a linear combination of the ranks of two methods with some coefficient that can be selected during validation.
The authors decided to conduct experiments on the most challenging tasks: determining toxicity (Paradetox, ToxiGen, Jigsaw, Twitter, ImplicitHate datasets), sentiment analysis (SST-5, Amazon datasets), and multiclass text classification (20 News Groups dataset). Using them, they trained two popular transformer models ELECTRA and BERT to solve the classification task and tried to determine wh ere they made mistakes.
As methods for evaluating epistemic uncertainty, scientists used three state-of-the-art methods (Mahalanobis Distance (MD), Robust Density Estimation (RDE) and Deep Deterministic Uncertainty (DDU)), and for evaluating aleatoric uncertainty — two methods based on model prediction probability (entropy and Softmax Response (SR)). The quality of the estimate was given by the RC-AUC metric.
A preliminary experiment on the synthetic Two Moons dataset, in which two groups of points on a plane act as examples, allowed one to visualize the effectiveness of the new method. The figure below shows that HUQ, which combines both methods, accurately identifies both areas of uncertainty and overcomes the shortcomings of each method applied individually.
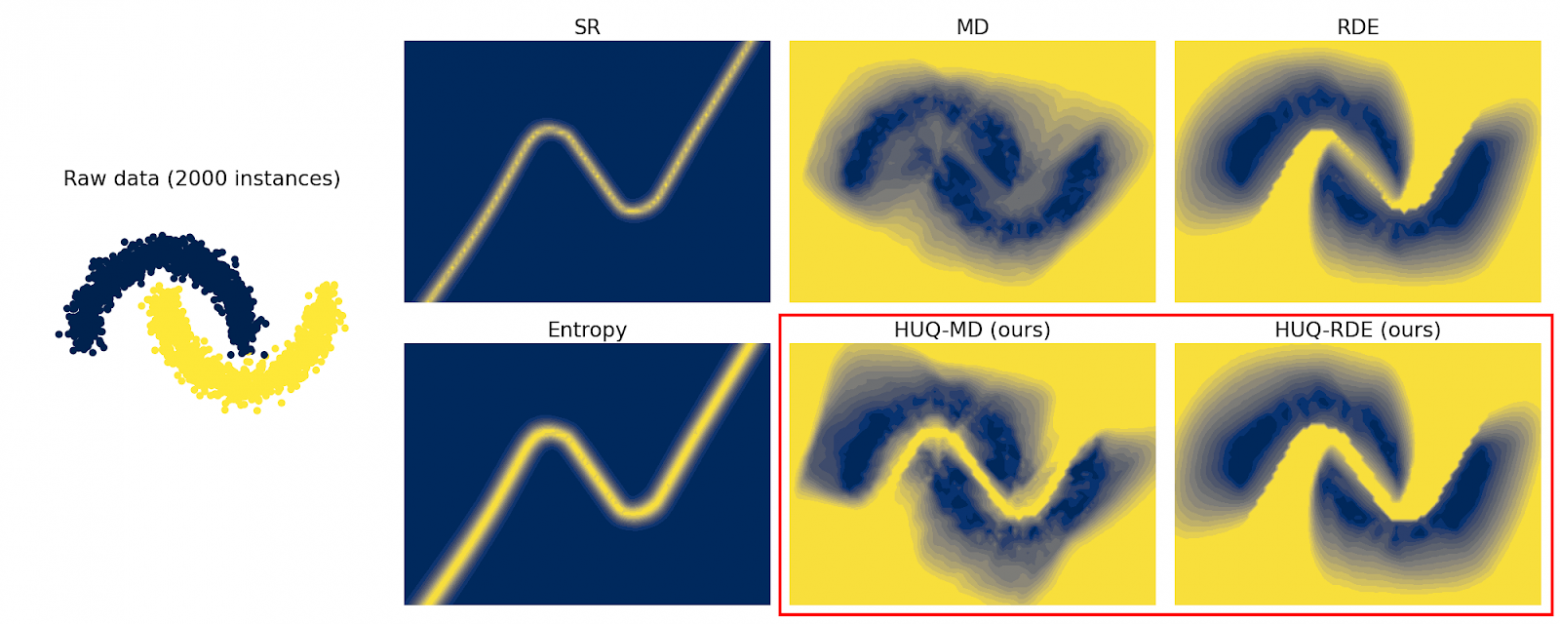
On the leftmost image, two classes are highlighted in color. For the other images, a more yellow color indicates higher uncertainty of the model for examples in that area
In the next step, the researchers compared HUQ with various state-of-the-art methods, including deep ensemble, a popular and accurate but computationally intensive method. Tests have shown that HUQ is generally the best or second-best method after deep ensemble. However, in contrast, HUQ works much faster, and on the SST5, 20 News Groups, and Paradetox datasets, HUQ even outperforms the ensemble.
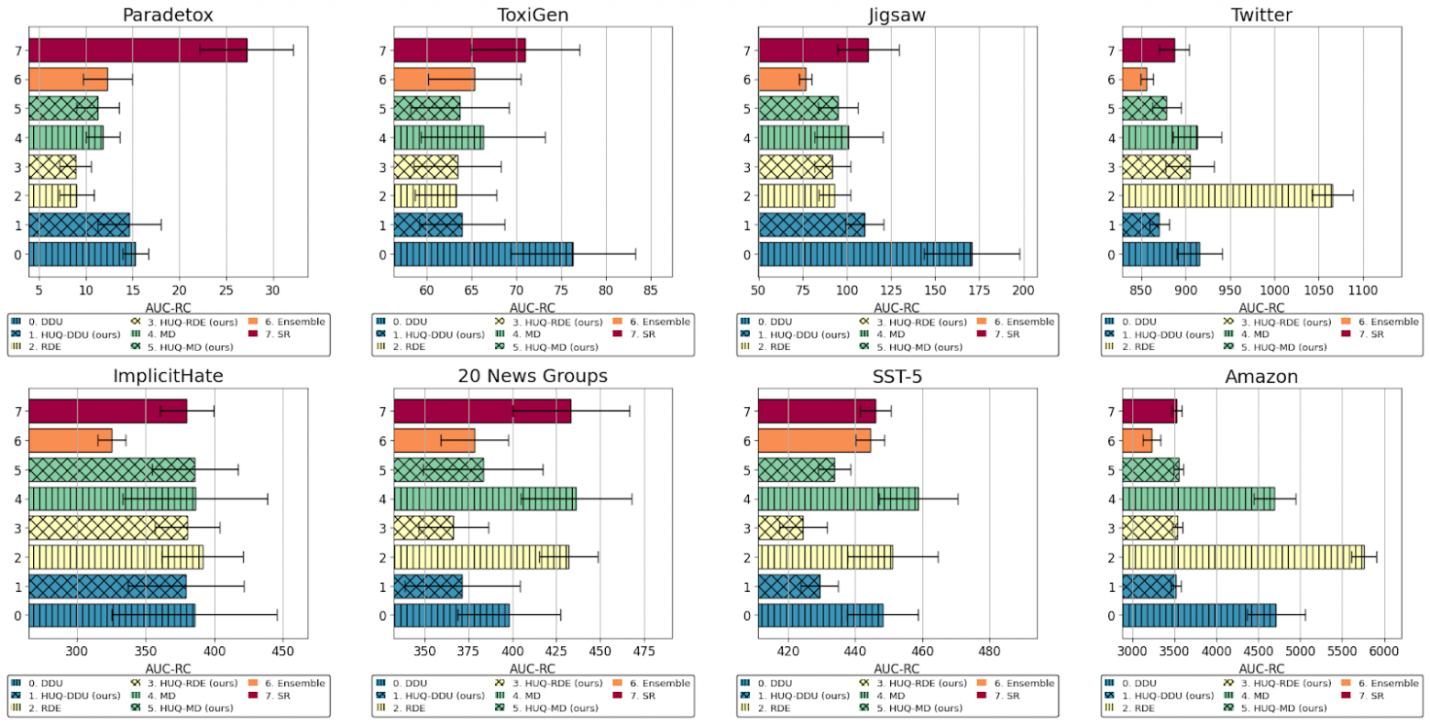
However, there are cases wh ere HUQ did not provide improvements compared to baseline methods. We conducted an analysis and noticed that such cases usually occur when there is a covariate shift in the data, i.e. the distribution of training and testing data differs. Finding a solution to improve the method's performance for such data is one of the directions for our future work.

Details of the work can be found in the article published in the proceedings of the ACL 2023 conference.