 Marat Khamadeev
Marat Khamadeev
Evergreeness of questions indicated LLM's self-knowledge
Large language models (LLMs) have found applications across a wide range of tasks, including answering user questions. As with many other applications, LLMs are prone to hallucinations — making up names, dates, facts, or other details. Another challenge in building question-answering systems based on LLMs is the problem of outdated knowledge.
A common way to address these issues today is through Retrieval-Augmented Generation (RAG). In RAG-based systems, external information (from files, databases, the internet, etc.) is retrieved and injected into the model's context to help generate more accurate responses.
While RAG is a powerful tool for improving LLM reliability, retrieving relevant context can take time. Moreover, RAG significantly increases the size of the input sequence, which may reduce answer accuracy for information located mid-context. For this reason, it is helpful to estimate in advance whether the model can answer a question using its internal knowledge (or self- knowledge) alone, without running inference.
This can be approached by analyzing the question itself — its length, number of named entities, their frequency characteristics, and other features. A team of researchers from Skoltech, AIRI, and MTS AI proposed focusing on whether a question is "evergreen" (unchanging) or "mutable". Evergreen questions are independent of time, place, or other context (e.g., "Who was the first president of the United States?"). In contrast, answers to mutable questions may vary depending on the time or conditions in which they are asked (e.g., "Who is the president of the United States?").
LLMs often struggle with mutable questions because, during pretraining, they encounter text referring to different people as presidents. Thus, answering questions like who currently leads the U.S. may yield inconsistent results. On the other hand, LLMs typically perform well on evergreen questions. Therefore, if a question is evergreen — for example, involving historical facts — LLMs can often provide a correct answer based on their knowledge, making the use of an RAG pipeline unnecessary.
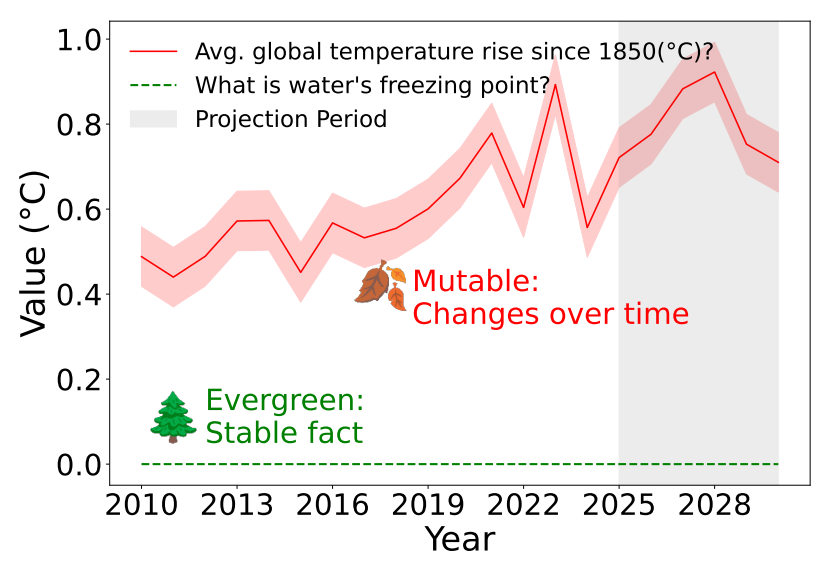
The question "What is the water’s freezing point under normal conditions?" is evergreen (green line). In contrast, "How much has the average global temperature increased?" is mutable (red line).
To assess how question type affects the chance of a correct answer without RAG, the researchers compiled a dataset called EverGreenQA. It contains 4,757 questions in seven languages, including Russian, and each question was manually annotated for mutability. Using this dataset, they developed the EverGreen-E5 classifier, which outperforms all existing few-shot LLMs.
The team then used the classifier to evaluate the self-knowledge of several popular LLMs and compared the results with other uncertainty metrics. They found that considering question constancy provides a more accurate assessment of a model’s knowledge, although the effect varied across models. Specifically, if a question is evergreen, an LLM is likely to know the answer. If it is mutable, the answer may or may not be correct. The team also discovered that this factor is good predictor of retrieval behavior of the proprietary GPT-4o model.
More details can be found in the paper. The dataset and classifier code are open-source and available on Huggingface.






