Marat Khamadeev
Marat Khamadeev
Information about nearest neighbors helped complete knowledge graphs more accurately
Knowledge graphs are a way of organizing structured information, in which entities are represented as nodes of a multi-relational graph, and their relationships are represented as its edges. The graph consists of a set of triplets: "object (head entity) — relation — subject (tail entity)". For example, the statement that Steve Jobs was born in San Francisco corresponds to the triplet "Steve Jobs" — "was born in" — "San Francisco".
This structure allows for a wide range of applications in various fields such as data mining, information retrieval, question answering, and recommendation systems. However, most real-world knowledge graphs suffer fr om incompleteness. In the example above, the system might know about Jobs' birthplace, but not about his place of death.
Algorithms for knowledge graph completion aim to solve this problem by learning embeddings, which are numerical representations of the graph's nodes. A trained model gathers structural and semantic information about the nodes and edges of the graph, allowing it to output answers based on similarity criteria.
Currently, methods for knowledge graph completion using language models are actively being developed. One advantage is their ability to leverage semantic information contained in the nodes and edges, as well as to work with new entities and relations that were not present in the graph during training. Approaches such as KG-BERT, KGT5, and others consider triplets as a text sequence and generate answers based on the parameters of the language model itself.
Researchers from MIPT, AIRI, and the London Institute for Mathematical Sciences proposed to take into account the nearest neighborhoods of graph nodes. According to their idea, including information about neighboring nodes and edges in the algorithm can improve the performance of graph completion. The authors proved this hypothesis for several popular language models, both in transductive and inductive settings.
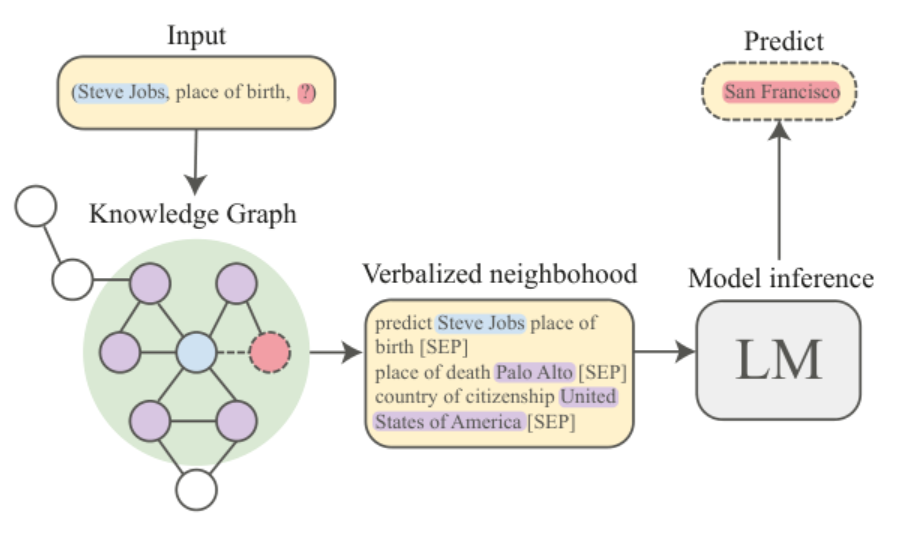
Graph completion pipeline. The new method extracts and verbalizes the neighborhood (green area) of a triplet head node (blue circle) from the Knowledge Graph. The Language Model uses verbalized input triplet and neighborhood to make predictions (red circle). Predictions can be used for question answering or knowledge graph completion.
In experiments, scientists used two subsets from the knowledge graph of real entities Wikidata. The first one — Wikidata5M — is one of the largest publicly available transductive knowledge graphs up-to-date. In transductive settings train and test entities and relations are from the same set. The second subset consists of large and small versions of the ILPC dataset — the largest among inductive benchmarks wh ere training occurs on one subgraph, and the model is tested on another with new nodes.
Experiments on these graphs showed that including neighboring nodes improves the quality of graph completion for language models with open-source models such as T5, as well as for proprietary models like OpenAI GPTs that are distributed as a model-as-a-service. The new approach demonstrated competitive performance on the ILPC dataset, while on Wikidata5M, researchers achieved the best result among generative link prediction models, outperforming models with many more parameters that rely only on graphs or language models. In the future, scientists plan to investigate the discovered effects depending on the model size and work on strategies for selecting nodes from the neighborhood graph and with knowledge graphs from other domains.
Details of the research can be found in the article published in the proceedings of the EMNLP 2023 conference, and the code is available in an open repository.