Marat Khamadeev
Marat Khamadeev
Persistent homology helped robust detection of AI-generated texts
Every year, new neural language models appear, and the texts generated by them become increasingly difficult to distinguish from those written by humans. Already, this greatly simplifies many areas of human activity. At the same time, the development of these technologies reduces the value and accessibility of human texts. This problem is particularly relevant to education and creative industries.
And so, experts in machine learning are challenged by the task of detecting AI-generated texts (artificial text detection, ATD). Such methods have been actively appearing in recent years, but most of them are designed to detect samples of individual generation models, either using the model itself or training on a dataset of its generations; they also have other limitations. Some researchers call on developers to inject some detectable artifacts into model generations that can be detected in a text sample — an idea, known as watermarking. Others think that propose a retrieval-based detector that could be implemented by text generation service providers: they should store the hash value of every text generated by their model and retrieve it by request. Finally, some believe that perfect artificial text detection is impossible.
A team of researchers from several Russian institutes is not ready to give up so quickly. Scientists have found that certain numerical representations of sufficiently long texts have a very remarkable geometry. In particular, as it turned out, one of its statistics — the so-called intrinsic dimensionality — can serve as a reliable indicator of whether the text is "natural" (that is, written by a human) or "artificial" (generated using a neural network model). Based on this observation, the team created a robust and universal detector for "artificial" texts.
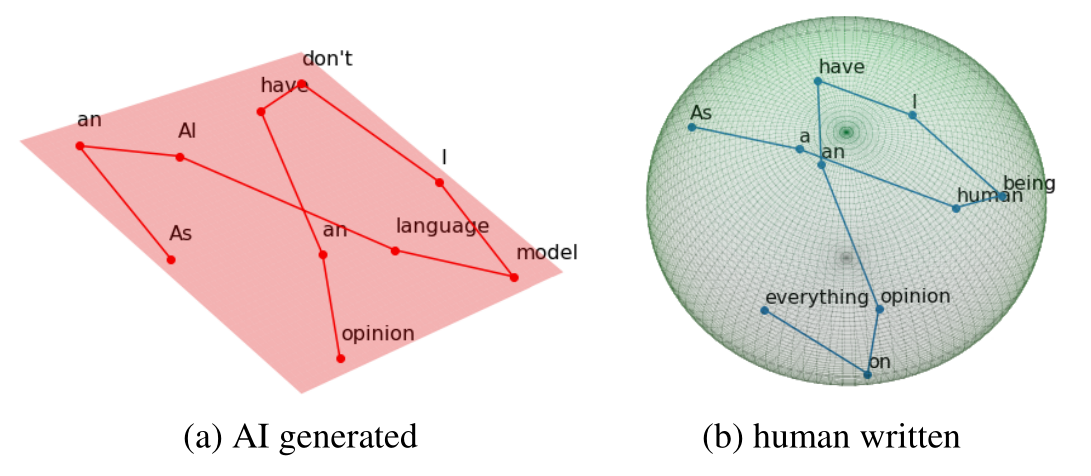
The main idea: real and artificial text have different intrinsic dimension
Other researchers working in this field have already suggested using the intrinsic dimension of data representations, neural network weights, or parameters needed to adapt to some downstream task. However, even if we assume that a dataset fits into some surface in a high-dimensional feature space, it is not easy to estimate its dimension due to various noise and the ambiguity of estimating a surface from a sparse set of points.
The authors of the new approach propose to estimate the geometry of every text sample as a separate object, naturally, if it is long enough (about 200 words or more) and fluent. Texts generated by modern language models usually do not contain grammatical, syntactical, or local semantic inconsistencies and generally meet these conditions.
Following the proposed method, firstly text is to be passed through a pretrained Transformer model, and the output is a set of contextualized embeddings — one for every token in the text (punctuation mark, word, or its part if it does not belong entirely to the limited vocabulary of the model). From a mathematical point of view, such an embedding is a vector of fixed length (or just a point in Euclidean space), the numerical value of which is determined by both the token itself and its context.
The next step is to estimate the dimensionality of the multidimensional surface on which this set of points lies which is considerable difficulty. The fact is that geometric representations of real data can have a complicated hierarchical structure, and their dimensionality depends on the scale at which they are studied. Therefore, as an approximate estimate, the same techniques are often used for estimating fractals' complexity.
There are many ways to estimate intrinsic dimensionality, and their differences are due to different assumptions about the structure of data. The article's authors compared the results of their application to context-dependent embeddings of texts and then proposed a new method based on the concept of Persistent Homology from Topological Data Analysis. As experiments showed, the proposed method — Persistent Homology Dimension (PHD) — was more stable to changes in style or length of the text, as well as different types of linguistic noise.
The researchers worked with two corpora of texts: "natural" and "artificial", that is, generated by various language models. The first was collected from texts of different styles and different sources, including articles from Wikipedia, posts on Reddit, and Q&A in various fields of knowledge from the StackExchange website. "Artificial" texts were created differently, depending on the specific task, but most were either expanded answers to questions or generated continuations of short excerpts (in two sentences). Different text generation models were used: GPT2-XL, OPT13b, GPT3.5.
The main thing that the experiments showed was a confident difference in intrinsic dimensionality for texts written by humans and machines. Italian and Spanish human texts had the highest dimensionality (10 ± 1), while Japanese and Chinese had the lowest (7 ± 1). However, regardless of the language, machine-generated texts demonstrated, on average, one and a half units less dimensionality with good statistical significance.
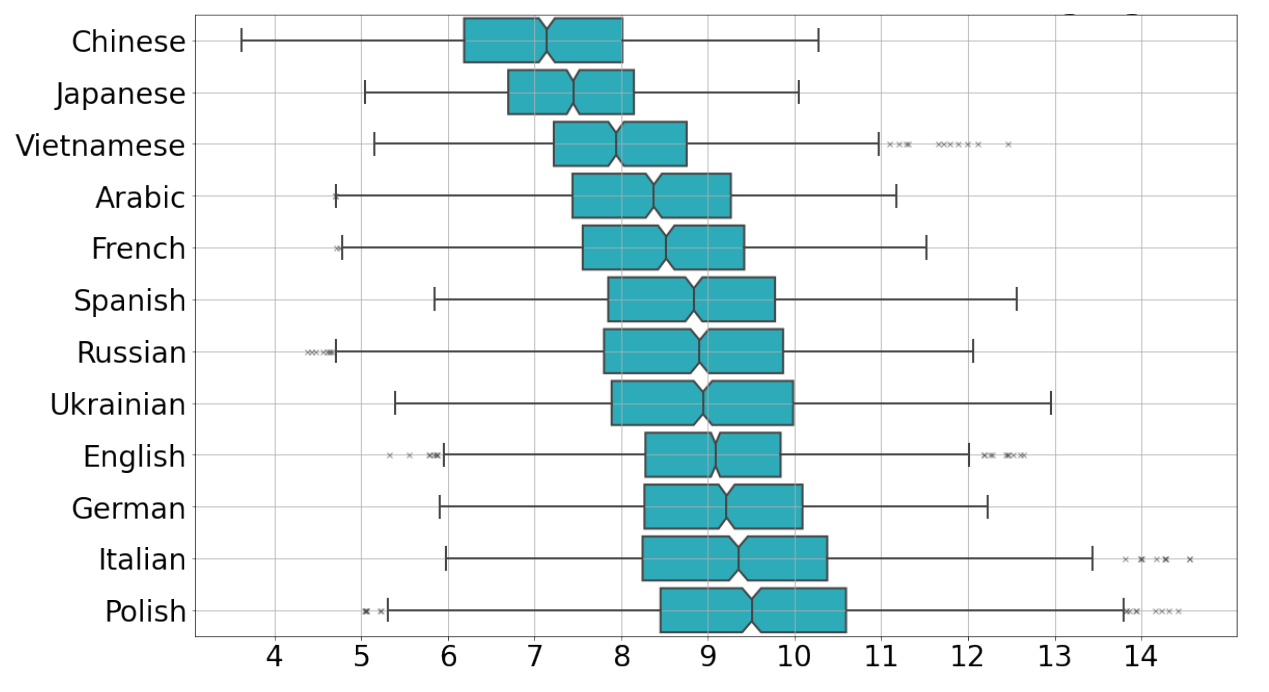
PHD distributions in different languages on Wikipedia data. Embeddings are obtained from XLM-RoBERTa-base (multilingual)
During experimental testing, the method proposed by the researchers outperformed other ATD methods, including GPTZero and the OpenAI detector introduced together with the ChatGPT model to reduce its expected social harm. The new approach demonstrated another important advantage: less non-native speaker bias present in ML-based artificial text detectors.
The code and data are available on GitHub, and details of the study can be found in the article published in the proceedings of the NeurIPS 2023 conference.