 Tatiana Zemskova
Tatiana Zemskova
Semantic graphs improved 3D scene understanding
An important skill that embodied agents (such as robots, unmanned vehicles, and similar devices) must possess is the ability to solve tasks at the intersection of computer vision and natural language. Such tasks include understanding and describing a 3D scene, as well as generating answers to questions about it. Large language models (LLMs) are well-suited as a key component of such intelligent systems. In this case, the description of the three-dimensional scene can also take the form of text; however, in practice, various learnable representations that encode objects and their relationships, such as point clouds or graphs, are increasingly used. In the latter case, nodes in the graph correspond to objects, and edges represent their relationships (for example, "the chair is on the floor").
The use of learnable representations allows for a more compact representation of the scene and improves the accuracy of task-solving, but existing approaches do not account for the semantic relationships between objects. This fact was noted by a team of researchers from AIRI and MIPT, who proposed a new graph representation of the scene in their method called 3DGraphLLM.
The primary goal of the authors was to demonstrate that the presence of semantic relationships between objects in the scene graph enables more effective differentiation between them based on textual descriptions, thereby enhancing the quality of spatial perception of the 3D scene by LLMs. To achieve this, they proposed organizing the representation in such a way that each object is associated with a subgraph containing the object itself and its nearest neighbors. A key role in this process is played by extracting embeddings of semantic relationships between objects, which the authors conducted using state-of-the-art methods such as VL-SAT.
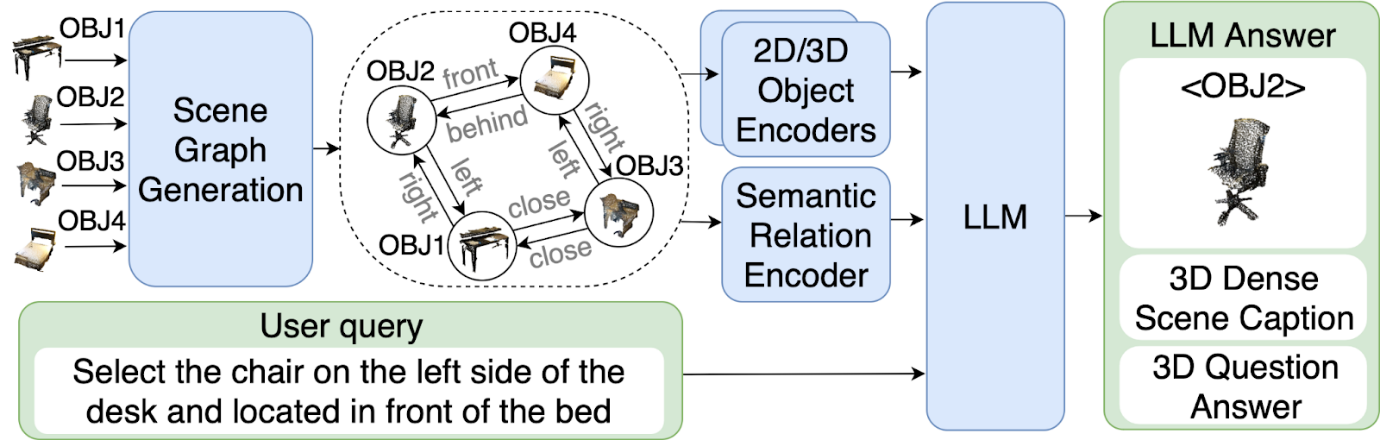
Diagram of the 3DGraphLLM approach
To verify the advantages of the new approach, the researchers solved several tasks using it and compared target metrics with existing methods. In particular, they asked the model to identify an area in the 3D scene corresponding to a complex natural language query and, conversely, to describe an object within a given spatial area. Another type of task involved generating answers to questions about the properties of the scene.

3DGraphLLM demonstrates the ability to utilize commonsense knowledge embedded in LLMs to solve tasks
The innovation proved to be most effective for solving the 3D detection task based on a textual query, but in other tasks, researchers also recorded metric improvements. The authors also showed that taking into account only two edges for each object in a subgraph demonstrates an acceptable trade-off between performance and model quality. In the future, they plan to reduce the number of tokens used for encoding connections, add automatic connection searching, account for dynamic changes in the graph, and expand the range of tasks solvable by this method.
The paper with this research has been accepted for publication in the proceedings of the ICCV 2025 conference, and the code and the model weights are open.






