Marat Khamadeev
Marat Khamadeev
A new System for Answering Simple Questions surpassed ChatGPT in accuracy
Over the past few years there has been an explosive growth in the quality of language models (LMs) capable of handling natural language queries. The most well-known of these is ChatGPT which has gained popularity far beyond machine learning community. It allows users to solve the widest range of tasks, from writing code to translating texts.
However, large LMs, including ChatGPT, often struggle with answering factual questions due to their training data quickly becoming outdated. If the answer to a question is clearly formulated in a regularly upd ated knowledge base, such as Wikipedia, or in a local knowledge graph (Wikidata), reliable access to it is required for such models to work effectively. Finally, searching for an answer among billions of facts can often be quite challenging.
A team of researchers from AIRI, Skolkovo Institute of Science and Technology, ISP RAS Research Center for Trusted Artificial Intelligence and Ural Federal University has been made efforts to address these limitations. They proposed a multilingual Knowledge Graph Question Answering (KGQA) technique that ranks potential responses based on the distance between the question’s text embeddings and the answer’s graph embeddings. Since a knowledge graph is a collection of subject-predicate-object triples, the new method is called multilingual triple match (M3M).
The scientists focused on simple questions such as “What is the capital of Great Britain?”. In this example “Great Britain” is a subject. This type of question is encoded in M3M using multilingual BERT. As a result, the question becomes represented with 768-dimensional vector. To project it to graph embeddings authors use three 2-layered perceptrons with ELU as an activation function. The answer is found by matching these vectors with embeddings from the knowledge graph.
The scientists chose the multilingual knowledge graph Wikidata for their work which also relies on linked Wikipedia articles. Each entity in such a graph is represented as a point in the embedding space. M3M ranks triplets from the graph by proximity to the desired triplet using cosine similarities and selects the very first one for the answer.
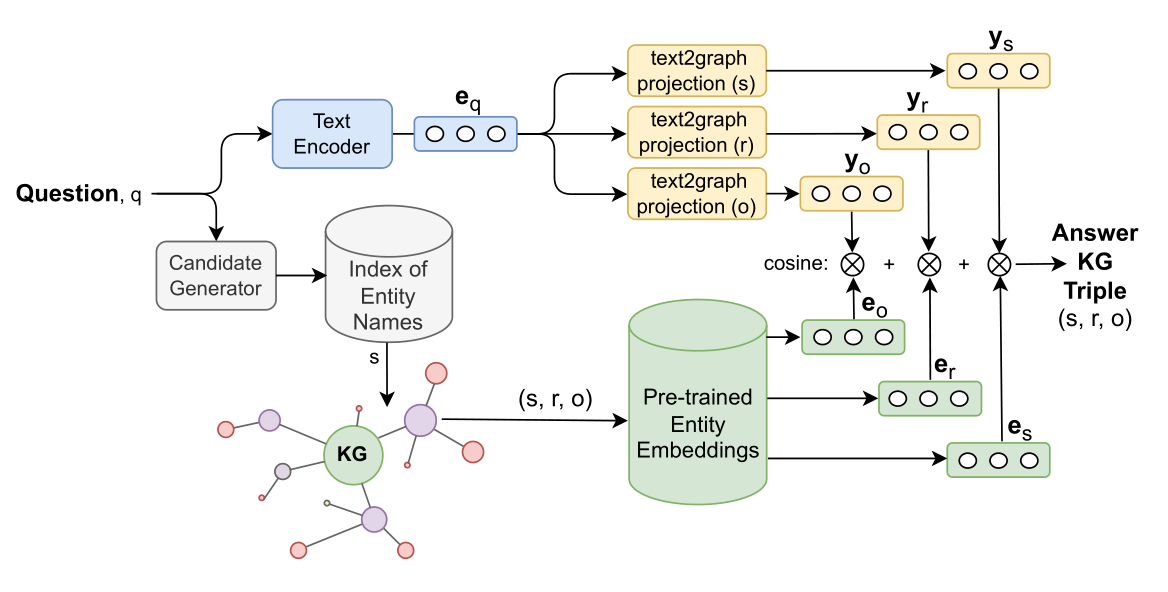
Workflow of M3M Knowledge Graph Question Answering system for simple questions
To illustrate the comparative advantage of the proposed method across diverse KG embeddings and languages team experimented with with several Wikidata-based datasets (SimpleQuestions, RuBQ, Mintaka-Simple), as well as with se t of specially constructed prompts for ChatGTP in order to evaluate its capabilities. The tests showed that M3M provides more accurate answers to simple questions than others, including various versions of T5, GPT-3, ChatGPT, KEQA, and QAnswer. On the Mintaka dataset M3M did not always have an advantage but was at least comparable in effectiveness to other models.
There are tasks that cannot be solved simply by increasing the size of models and one such task is knowledge updating, as the "intelligence" of language models is limited by the date of their training datasets. The simplest solution would be to give these models access to the internet and allow them to google new and relevant information — but then there is a risk of obtaining unreliable facts. I believe the way to bypass this limitation is to base on verified and constantly updated knowledge graphs.

The researchers uploaded the source code on Github. More technical details can be found in the paper published in the proceedings of the ACL-2023 conference.