Marat Khamadeev
Marat Khamadeev
Using vector symbolic architectures to obtain disentangled representations
Good data representation for machine learning algorithms is one of the key success factors for modern approaches. Initially, the construction of good representations consisted of feature engineering, i.e., the manual selection, creation, and generation of such features that allow the model to solve the main problem successfully. Current models, however, rely on learning representations fr om data.
Nowadays, a good representation can be considered in several ways: proximity of representations for semantically related objects, identification of common features in objects, preservation of a complex structure with a decrease in dimension, and disentanglement of representations. The latter means that a representation should factorize (disentangle) the underlying generative factors so that one variable capturing at most one factor, a single variable should capture i.e., each underlying generative factor and information the representation captures about the underlying generative factors should have completeness.
The disentangled representation may potentially improve generalization and explainability in many machine learning tasks: structured scene representation and scene generation, reinforcement learning, reasoning, and object-centric visual tasks.
Vector Symbolic Architecture
Modern disentangled representation learning approaches use the localist representation wh ere single vector components perform representation of information. Instead, Aleksandr Panov fr om AIRI and FRC CSC RAS and his colleagues propose to use the principles of Hyperdimensional Computing or Vector Symbolic Architecture (VSA). VSA is a framework in which symbols are represented by vectors of high dimensions and which allows one to operate with symbols as vectors.
In VSA, the seed vectors, from which the description of an object is formed and which characterize its features, are usually obtained by sampling from a predetermined high-dimensional space. They are fixed and are not learned from data. VSA uses that with an extremely high probability all seed vectors from high-dimensional spaces are dissimilar to each other (quasi-orthogonal), which allows us to reduce the manipulation of the symbols to vector operations. These vectors have the same dimension as the resulting representation.
All properties of an object processed with a disentangled representation are, thus, mapped in the latent space wh ere they can be manipulated easily. It could be, for example, features of elements of a scene: color, shape etc. This opens an opportunity to exchange features between objects from different images (target and donor).
Feature exchange
The team made it for scenes with simple geometric figures. First, each object is mapped in the latent space using the autoencoder. Then, using the Generative Factors Projection module, an intermediate value vector is obtained. This vector is then fed into the Generative Factor Representation module, which uses the attention mechanism to represent the value vector as a linear combination of seed vectors. This combination is the disentangled representation of an object into a latent space.
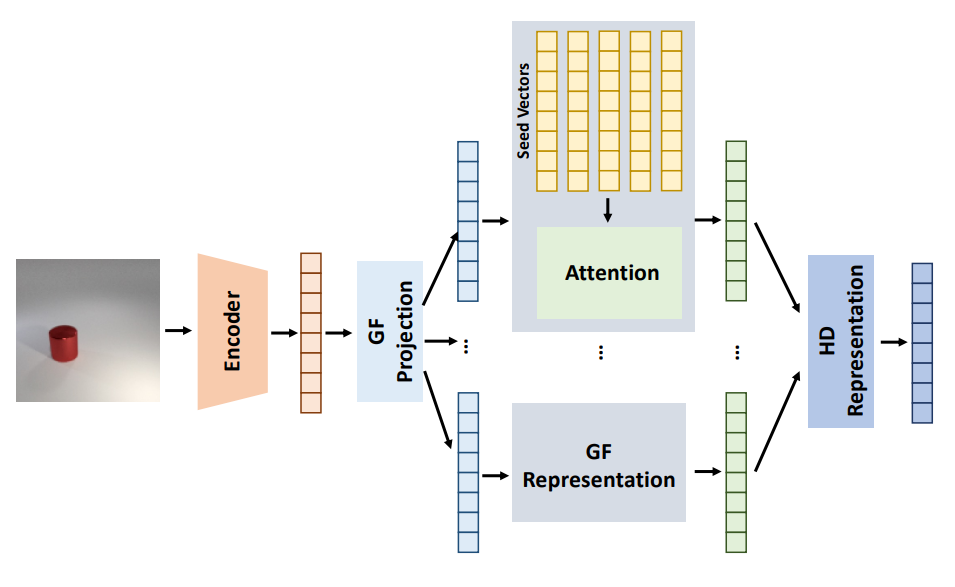
Obtaining an hyperdimensional representation of an object
To demonstrate work of the new algorithm authors applied it to the objects from dSprites and CLEVR datasets. Each object was presented by vectors corresponding to several generative factors: “Shape”, “Color”, “Size”, “Material”, “Orientation”, “Coordinate x” and “Coordinate y”. Scientists exchanged features between target and donor images presented by vectors and then reconstructed them.
In case of dSprites dataset all features were correctly transferred from the donor image with insignificant errors. Researchers marked that “Orientation” feature is strongly related to the “shape” feature unlike the others features. They explained this by the symmetry features of the figures (square, oval and more). For figures from CLEVR the algorithm works well with the “Color”, “Size”, and “Material” properties but had problems with reconstruction when changing coordinates.
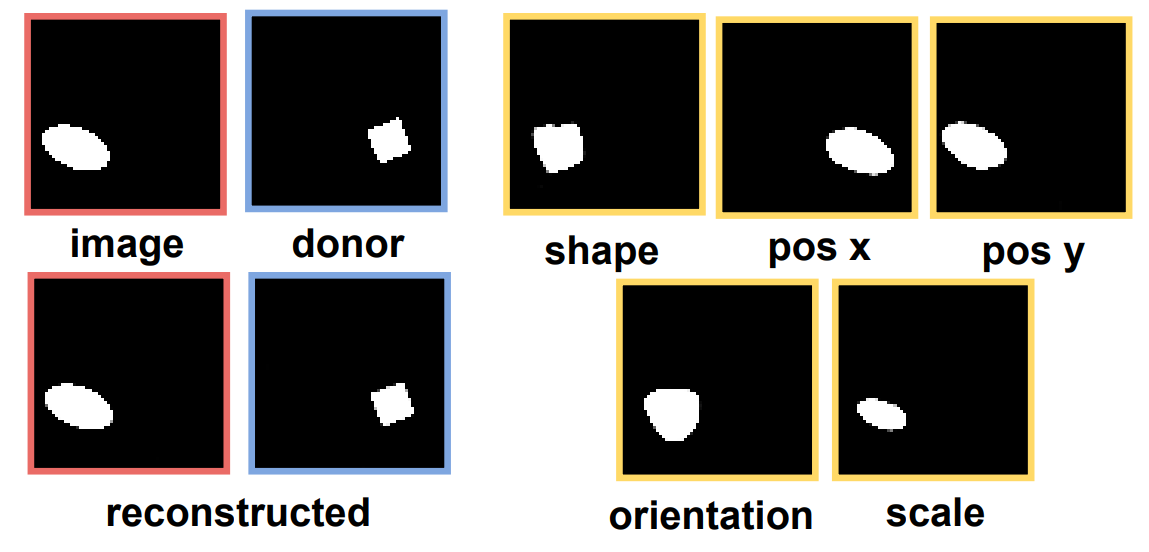
Image reconstruction of objects with modified values of generative factors (yellow) for dSprites paired dataset. The target object (red) differs from the donor object (blue) in all factor values
The approach based on VSA leads to distributed representations that allows one to reduce the change in the properties of an object to manipulation with its latent representation using vector operations. At the same time, for real data it is necessary to know in advance the number of generative factors. The generalization of the proposed model to this case is a direction for further research of the team.
More details can be found in the article published in the Proceedings of the ICLR 2023 conferenc