 Aydar Bulatov
Marat Khamadeev
Aydar Bulatov
Marat Khamadeev
A new benchmark will test the ability of large language models to search for information in long contexts
In language models, the context refers to the length of the text input they can process and comprehend the information contained within. Increasing the context allows for a broader range of scenarios in which a large language model (LLM) can be used out-of-the-box without retraining on new data domains. Long contexts also enable complex step-by-step reasoning or the application of models in other modalities.
Today, the sizes of LLMs developed by laboratories worldwide show rapid growth. This increases their capabilities and skills but simultaneously motivates a proportional increase in the context window and requires its effective use.
One of the most popular ways to test such efficiency is the Needle in a Haystack benchmark. It assesses the model's ability to find small pieces of information in contexts up to tens of millions of tokens long. Today, Needle in a Haystack has become a standard for many developers, leading them to often include similar tasks in their training datasets, retraining their models, and making benchmark metrics less objective. Unfortunately, there are not many good non-synthetic benchmarks that work with long contexts to provide additional assessments of LLM performance with context.
This issue has seriously concerned researchers from AIRI, MIPT, and the London Institute of Mathematical Sciences. The result of their work is BABILong — a more complex version of the Needle in a Haystack benchmark that tests models' ability to perform logical reasoning tasks in long contexts.
The name of the new benchmark reflects its focus on large contextual windows as well as its use of tasks from the bAbI dataset, created for testing intelligent systems. BABILong consists of 20 tasks that evaluate basic calculus, information integration from multiple facts, and logical reasoning. The conditions and questions of the tasks were embedded within books from the PG19 dataset.
The authors tested three dozen relevant models, including both proprietary (GPT-4o, Gemini) and open-source (Llama 3.1, Qwen 2.5) ones. It turned out that even the best among them demonstrated a significant drop in quality as context length increased. Even less success was achieved by methods that expand context using Retrieval-Augmented Generation (RAG).
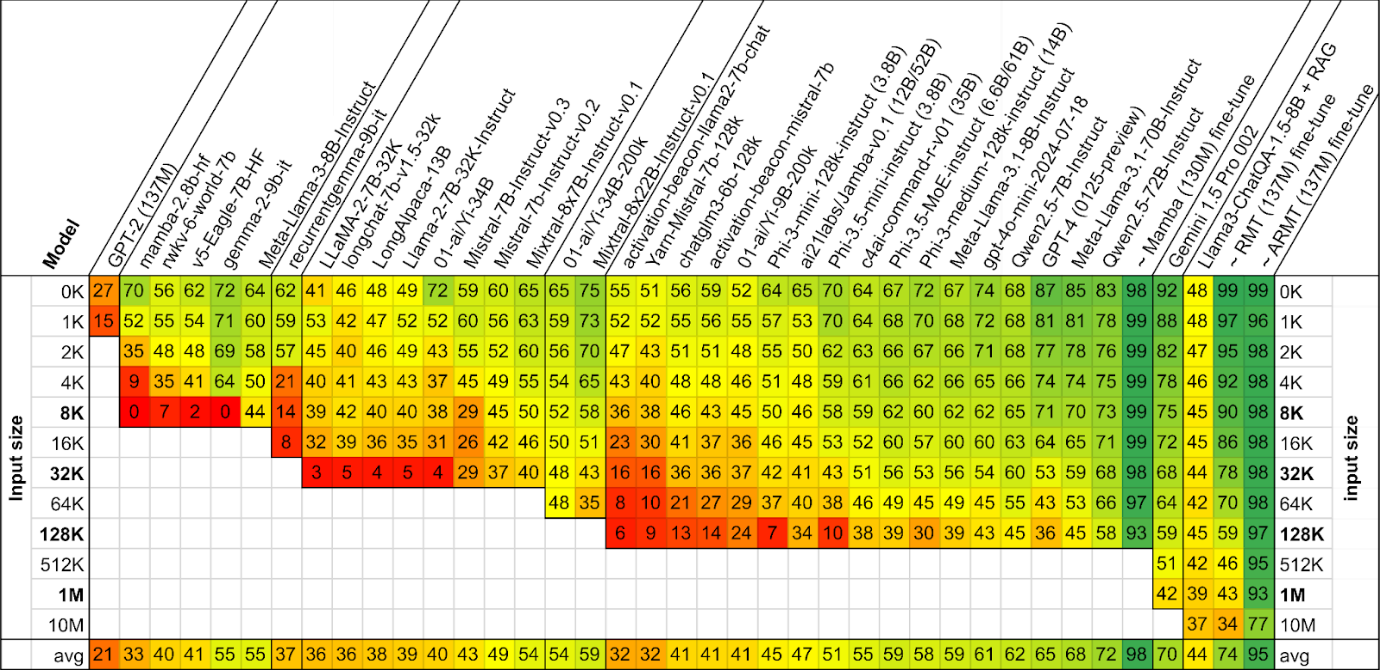
Testing models on BABILong sorted by context length. The color and numbers indicate the percentage of correctly solved tasks at that length. The symbol “~” denotes specially trained models.
Researchers also examined how models enhanced with recurrence at the segment level perform on BABILong. We have previously discussed this new method of increasing context called Recurrent Memory Transformer (RMT), developed by the same team. The scientists experimented with architectures and found that the GPT-2 model, augmented with an associative version of RMT (ARMT), maintains a quality level of 80% up to a context length of 50 million tokens.
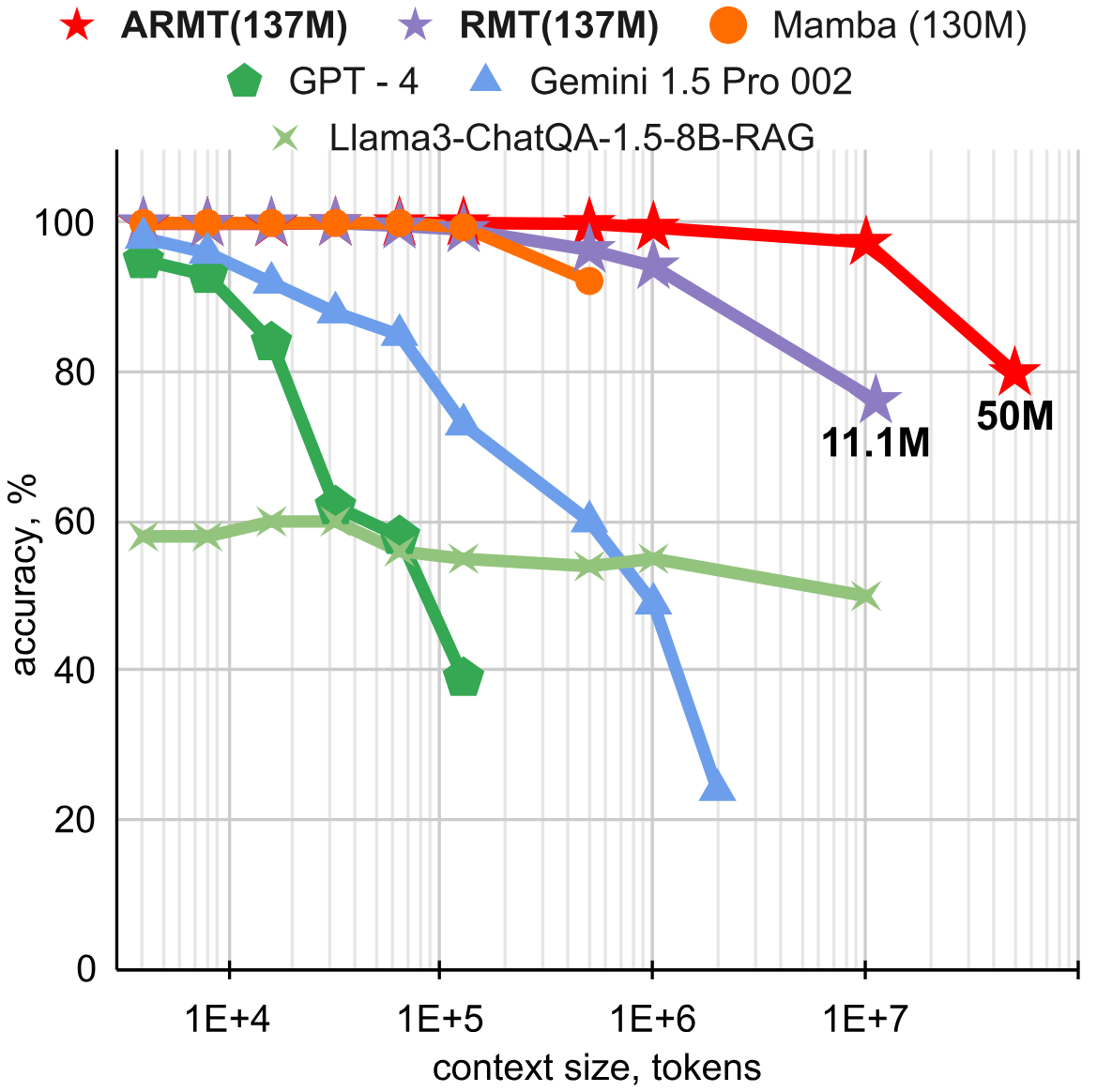
Comparison of RMT and ARMT on the QA1 task of the BABILong benchmark
The research was published in the proceedings of the NeurIPS 2024 conference.






