Alla Chepurova
Alla Chepurova
Large language models proved capable of populating knowledge graphs
Most of humanity's knowledge in our century is stored in the form of text. This is the most natural way for us to express information after speech. However, it is not very well-structured, making it not the most optimal way to organize a knowledge base.
Instead, it is preferable to use knowledge graphs (KGs) — data structures in which entities and their relationships are represented as nodes and edges. In this form, a knowledge graph can be constructed as a set of triplets referred to as "subject, relation, object". The high degree of organization of information in graphs makes them suitable for search, question-answering, recommendation systems, and other applications. Furthermore, linking large language models (LLMs) with knowledge graphs can help reduce hallucinations of the latter.
A significant drawback of graphs is the need for experts who manually populate them. Therefore, developing methods to automate this work is highly relevant.
Since knowledge extraction often occurs from texts, it was natural to attempt to do this using LLMs. Recent research has shown that it is possible to eliminate the need for training or fine-tuning models by applying in-context learning and following instructions. Nevertheless, in the literature, this task was considered asymmetric, and the very idea of building knowledge graphs using LLMs was deemed unpromising.
Researchers from MIPT, AIRI, and the London Institute of Mathematical Sciences have proven otherwise. They created an algorithm called "Prompt Me One More Time", which successfully populates knowledge graphs using the approach described above.
The new method consists of three steps. In the first step, the language model extracts candidate triplets from the text. The names of entities and relations may not directly match the formats used in the chosen KG, so in the second step, the algorithm normalizes them to the required format. Finally, normalized candidates are filtered for consistency with the KG ontology, meaning the constraints on which entities can be connected by which relationships.
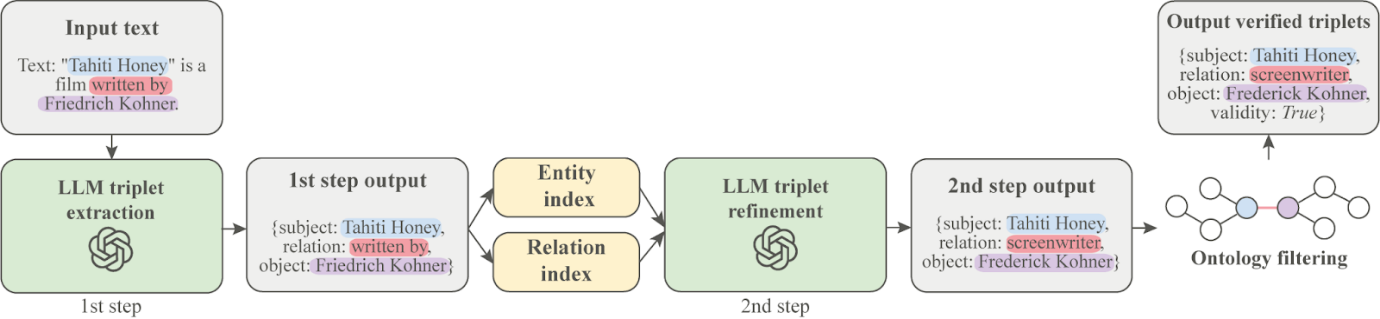
Proposed pipeline for KG extension
To validate the new approach, the authors chose to populate the largest open-source knowledge graph, WikiData, and for all steps except the last one, they used the OpenAI model gpt-3.5-turbo. To conduct a proper evaluation of effectiveness, the researchers selected a synthetic dataset called SynthIE and compared their algorithm with a specialized model, SynthIE T5-large.
During their work, it became clear that in SynthIE, triplets in the annotations often did not match the texts. To address this shortcoming, the researchers manually added texts from Wikipedia about the entities from such triplets. A comparison on the corrected dataset along with manual evaluation by three annotators showed that "Prompt Me One More Time" outperformed SynthIE T5-large in task performance.
Moreover, the sets of triplets that were correctly reconstructed by both approaches differed significantly. The researchers concluded that developing combined approaches could generally enhance the performance of the method.
More details can be found in the paper presented at the TextGraphs-17 workshop at ACL-2024.