 Marat Khamadeev
Marat Khamadeev
The sparse parameter space helps to make transformers more compact
In recent years, the sizes of models in machine learning, especially transformers, have been steadily increasing. Alongside this, the costs of training them and the need for large datasets are also growing, which not all research groups can afford. Finally, the memory requirements for deploying such models are becoming so large that they can no longer be run on individual graphics cards, reducing the scenarios for their practical use.
Instead of training from scratch, it has become usual practice to fine-tune pre-trained models on a downstream task. These models contain a vast amount of diverse knowledge and are called foundation models. Their weights are often publicly available and can be downloaded by anyone interested.
Fine-tuning significantly reduces the training time. However, there is no gain in GPU memory usage since for each trainable layer in the model, the computational graph still needs to store both the weight matrix and the gradient matrix. Parameter-efficient fine-tuning (PEFT) methods provide memory savings by storing gradients only for a portion of the weights.
There are several approaches to PEFT. For instance, the method LoRA, which has gained popularity in the ML community, represents the correction matrix as a product of two low-rank matrices, significantly reducing optimization complexity. However, in the case of transformers, this and many other methods are typically applied to the attention module while ignoring the multilayer perceptron (MLP) blocks.
A team of researchers from AIRI and Skoltech noted this fact. The scientists started from the assumption that there exists a basis in which the gradient matrix has a highly sparse structure, which can be used to reduce the number of parameters during training.
They introduced a new PyTorch layer class called SparseGradLinear, which transitions weights to this sparse space, computes gradients within it, and then returns. In doing so, the researchers calculated transition matrices by factorizing a tensor assembled from the gradients of MLP layers. It turned out that these matrices are identical across the model for layers of a given type, meaning they only need to be found once before the fine-tuning procedure. The new method was named SparseGrad.
The authors experimented with three open models: BERT and RoBERTa base and large, and the decoder architecture LLaMa-2. The GLUE benchmark was used to evaluate the first two models, while the OpenAssistant Conversations corpus and questions from Inflection-Benchmarks were utilized for the latter. It turned out that SparseGrad allows reducing the number of trainable parameters to 1% of the original without significantly degrading the model. Experiments showed that under comparable conditions, the new approach outperformed current popular methods in metrics: reparameterization-based LoRA and selective MeProp.
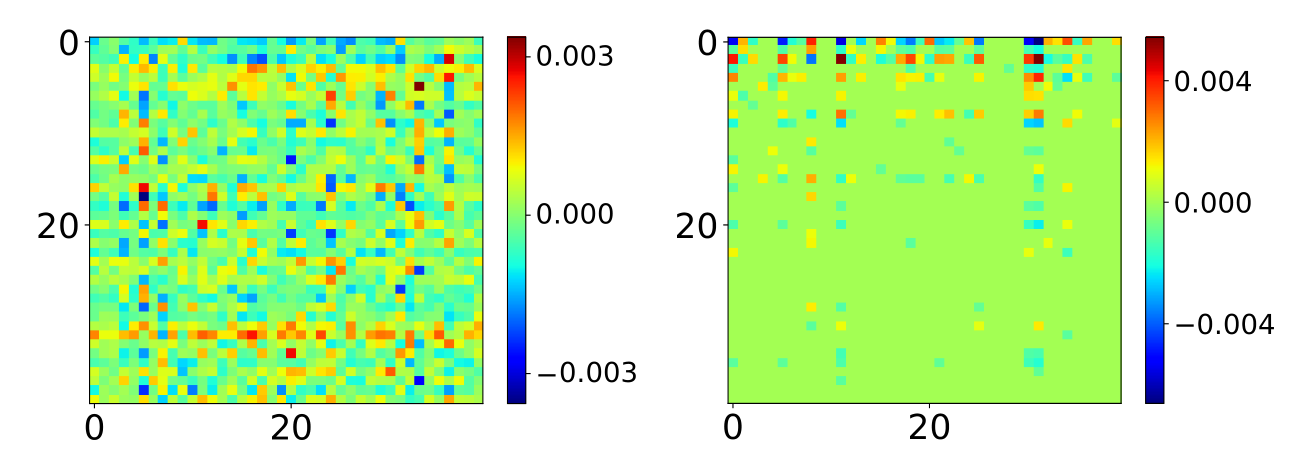
Gradients on the 5-th BERT MLP before (left) and after (right) transformations with SparseGradLinear
The research was published in the proceedings of the EMNLP 2024 conference on natural language processing.






