Marat Khamadeev
Marat Khamadeev
How to make ensembles in transfer learning more efficient?
Good training of neural networks for specific tasks is only possible with a high-quality and rich dataset. Unfortunately, in practice, collecting such data is too expensive or even impossible. To address this difficulty, experts apply various techniques, such as domain adaptation of the model using transfer learning.
The essence of this approach is to pre-train the model on a large but general dataset and then fine-tune it using a small but targeted domain. This technique works because pre-training allows the model to learn common properties that are inherent in all objects, including the target ones. For example, before training a neural network to draw portraits in the style of famous artists, it can be fed by photos and drawings of many people, as in all cases faces will have similar features. Recently, we reported how scientists from AIRI and their colleagues were able to optimize this process for generative adversarial networks, reducing the number of parameters by five thousand times.
Parallel to this, experts aim to increase the accuracy of models by assembling them into ensembles. This involves taking several neural networks, each initialized randomly, and training them on one task. Averaging the predictions of such an ensemble shows higher quality than predicted with a single neural network.
A team of scientists led by Dmitry Vetrov is looking for ways to effectively combine transfer learning and ensembling. Typically, two opposing strategies are identified when combining these techniques: local and global deep ensembling (DE). In local deep ensembles, only one model checkpoint is pre-trained, after which each network in the ensembles is fine-tuned from this checkpoint. As a result, the networks are similar or, from the loss landscape perspective, are in the same pre-training basin — hence the strategy is called local. In the global method, each neural network is pre-trained independently, which provides greater diversity and, as a result, improves prediction quality. However, global DE is significantly more expensive to train than local DE.
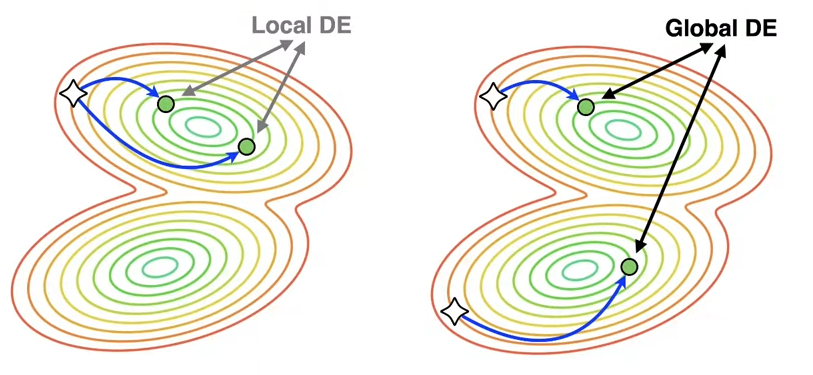
The difference between local and global deep ensembles in the weight space of neural networks. Pre-trained checkpoints are denoted by stars, fine-tuned models by green dots, and the optimization trajectory by blue arrows.
Researchers aimed to combine the advantages of both strategies and turned to the Snapshot Ensembling (SSE) method used in deep ensembles, which cyclically adjusts the learning rate. In this technique, the neural network can leave a local minimum at learning rate peaks, and a checkpoint can be fixed at the nearest minimum. In practice, the effectiveness of SSE depends on hyperparameters such as the amplitude and period of cycles.
During experiments, scientists confirmed that the effectiveness of applying SSE to transfer learning depends on hyperparameters and reaches a maximum at a certain optimum. However, this maximum does not provide any advantage over traditional local DE. The authors then noticed that ordinary SSE trains the networks consequentially, leading to model degradation at high learning rate that could potentially provide greater diversity.
Instead, they proposed a parallel variant, fine-tuning the first model from the pre-trained checkpoint in a usual way and then training all the following models, independently initializing them with the first fine-tuned one. As this scheme has a star-shaped form in the weight space, the method was named StarSSE. Experiments showed that the new approach improves local DE performance under certain hyperparameters.
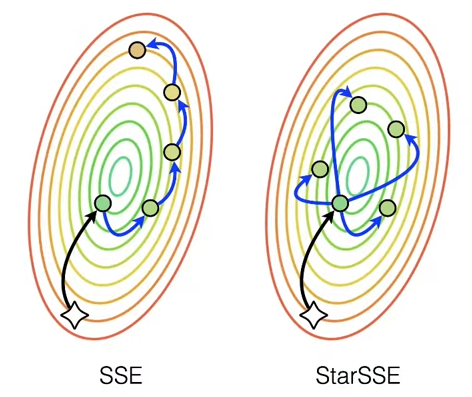
Difference between SSE and StarSSE
In addition, the authors proposed a way to speed up inference, that is, the final performance of the trained model. To do this, they used so-called model soups, an ensemble technique that averages not the predictions, but the weights themselves. Calculations made by the researchers showed that soups of StarSSE models work more efficiently than ones of SSE and even local DE.
The authors’ code is open for download on GitHub; details of the research can be found in the article published in the proceedings of the NeurIPS 2023 conference.