 Nikita Dragunov
Nikita Dragunov
Sentence-level text processing proved to be comparable to traditional LLMs
Most modern large language models operate in an autoregressive, token-by-token mode, generating the next token in a sequence based on the previous ones. This approach simplifies training and enables models to produce coherent text, but for long sequences, it leads to the problem of quadratic growth in computational complexity.
Recently, a method called Large Concept Models (LCM) was proposed. Its authors attempted to overcome this difficulty by moving from token-level text processing to processing embeddings of entire sentences. The researchers experimented with several architectural designs, the main ones being an autoregressive approach with an MSE loss and a diffusion-based approach. Although this greatly reduced the length of the processed context (instead of dozens or hundreds of tokens, only one embedding is processed), autoregressive LCMs showed low stability, while their diffusion-based variant had no speed advantages.
Researchers from the Architectural Insights team at the FusionBrain AIRI lab took the next step in developing the LCM idea and proposed a new model called SONAR-LLM. The suggested architecture is based on an autoregressive transformer decoder that works with sentence embeddings and uses a cross-entropy loss function during training.
In SONAR-LLM, text is split into sentences, each of which is encoded into a 1024-dimensional vector using the frozen SONAR encoder developed by the authors of the original idea. SONAR-LLM then generates the embedding of the next sentence, which is fed into the frozen SONAR decoder. During training, teacher forcing is applied: at each step, the SONAR decoder receives not only the sentence embedding but also the previous tokens of the correct sentence and predicts the next token. Finally, cross-entropy is minimized on the predicted token with respect to the model parameters.
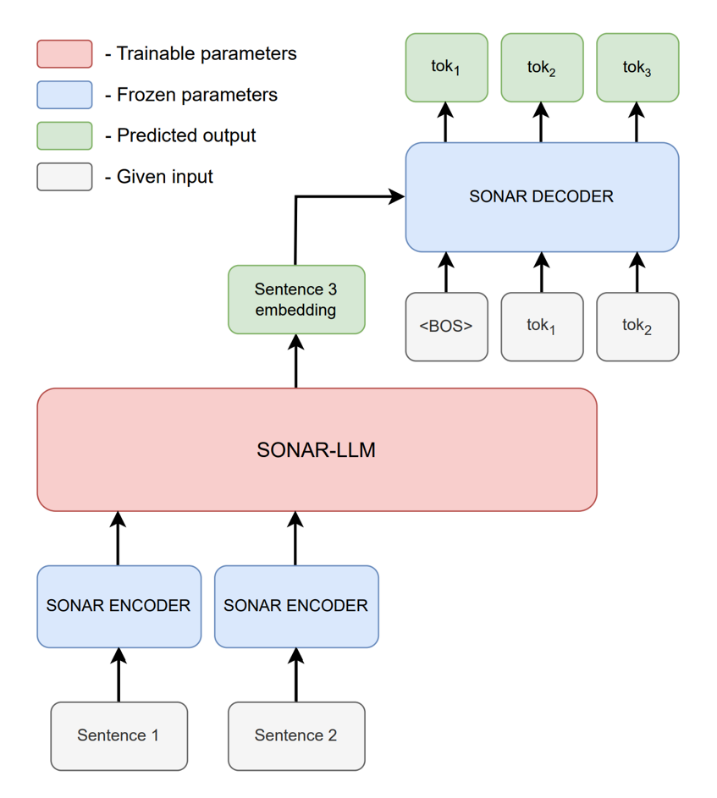
SONAR-LLM architecture
AIRI researchers compared SONAR-LLM with the original LCMs as well as with a traditional LLM (Llama 3 architecture) across several criteria: scalability, generation quality, summarization capability, and performance on long contexts. The new model did not always outperform LLMs in the tests, but consistently outpaced the original LCMs. These studies showed that sentence-level text processing could become a serious alternative to the conventional token-by-token approach.
More details can be found in the paper, and all code is available on GitHub.






