 Andrey Galichin
Andrey Galichin
Reasoning-related features discovered in large language models
The original goal of language models was simply to predict the most likely word (token) in a given sequence. Applying the transformer architecture, along with scaling up model sizes and training data, led to a revolutionary improvement in the quality of generated texts, which are almost indistinguishable from human writing.
Today, a new stage in the development of large language models (LLMs) is linked to the emergence of reasoning behavior, where the neural network breaks a task into multiple steps and engages in reflection. Popular models that have demonstrated this behavior include OpenAI’s o1 and DeepSeek-R1.
Despite the impressive progress in capabilities, relatively little is known about how reasoning is encoded inside LLMs. To interpret this behavior, a team of researchers from AIRI focused on the fact that, during reasoning, models often use words such as “wait”, “maybe”, “alternatively”, “however”, and similar ones that explicitly signal uncertainty and self-reflection.
The scientists used the Sparse Autoencoders (SAE) method, which decomposes model activations into sparse and interpretable features corresponding to specific human concepts. They applied this technique to representations of DeepSeek-R1-Llama-8B, extracting about 65,000 features. Among them, the authors identified those that are active when generating reasoning-related words. After manual inspection, they were able to find features associated with uncertainty, exploratory thinking, self-correction, and other characteristic behaviors.
To prove that the identified features are genuinely linked to reasoning, the researchers conducted a series of steering experiments. They found that strengthening these features led the model to generate reasoning that was 13–20% longer and to solve mathematical benchmark problems more accurately. At the same time, they discovered that such features emerge only in models specifically fine-tuned for reasoning.
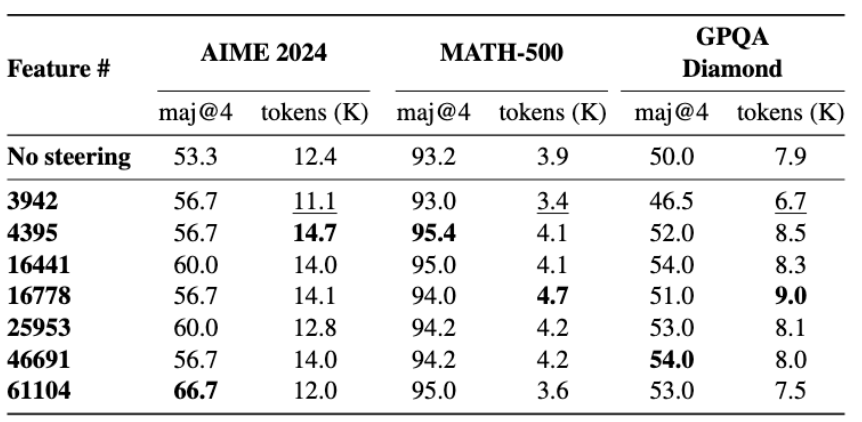
Results of amplifying certain features on mathematical benchmarks. Both quality and response length increase.
The researchers note that the work on interpretability is still far from complete. In particular, not all reasoning-related features have been reliably identified. Moreover, the SAE method itself has limitations.
More details can be found in the paper, and the code is available on GitHub.






